计算机编程
The Art of Computer Programming
- Numbers Every Programmer Should Know (~2026)
- P0. 编程原则
- C1. 计算机基础
- P3. 性能优化
- T4. 论文、访谈或演讲
- C5. 最喜欢的语言:面向现代的C++
- Rust programming
- Golang Programming
- Problem Solving
- 技术工具: 喜鹊开发者
- 其他
- 编程杂谈
- 待整理
- 编程工具箱
Numbers Every Programmer Should Know (~2026)
| Operation | latency | Notes |
|---|---|---|
| L1 cache reference | 0.5 ns | 3-5 cycles( pointer dereference 3~4) |
| L2 cache reference | ~2-4 ns | 12~14 cycles AMD, 16-17 cycles Intel |
| Branch mispredict | ~3-5 ns | 10-20 clock cycles, avg:18 |
| Mutex lock + unlock(round-trip) | ~20-60ns | 60-200+ cycles |
| Main memory reference | ~70–110 ns | 350–550 cycles |
| Context Switch | 600ns ~ 2 μs | 3k ~ 100k cycles, L1/L2/L3 + TLB miss |
| Compress 1K bytes with Zippy | 3,000 ns / 3 μs | - |
| Send 1KB over 1 Gbps network | 10,000 ns / 10 μs | - |
| Read 4K randomly from SSD* | 150,000 ns / 150 μs | ~1GB/sec SSD |
| Read 1 MB sequentially from memory | 250,000 ns / 250 μs | - |
| Round trip within same datacenter | 500,000 ns / 500 μs | - |
| Read 1 MB sequentially from SSD* | 1,000,000 ns / 1,000 μs / 1 ms | ~1GB/sec SSD, 4X memory |
| Disk seek | 10,000,000 ns / 10,000 μs / 10 ms | 20x datacenter roundtrip |
| Local LLM, generate 1 token | 15,000,000 ns / 15,000 μs / 15 ms | Small model on consumer GPU (2026) |
| Read 1 MB sequentially from disk | 20,000,000 ns / 20,000 μs / 20 ms | 80x memory, 20X SSD |
| Frontier LLM, generate 1 token | 20,000,000 ns / 20,000 μs / 20 ms | Hosted model output (2026) |
| Local LLM, time to first token | 75,000,000 ns / 75,000 μs / 75 ms | Small model, short prompt (2026) |
| Local LLM (CPU), generate 1 token | 100,000,000 ns / 100,000 μs / 100 ms | Small model, no GPU (2026) |
| Send packet CA->Netherlands->CA | 150,000,000 ns / 150,000 μs / 150 ms | - |
| Fast LLM, time to first token | 250,000,000 ns / 250,000 μs / 250 ms | Specialized inference hardware (2026) |
| Frontier LLM, time to first token | 1,000 ms | Short prompt, no cache (2026) |
At ~4–5.5 GHz boost clocks common on latest chips, 15 cycles ≈ 3–4 ns; 20 cycles ≈ 4–5+ ns. 1 ns ≈4–5.5 个 cycles
Branch misprediction penalty: modern x86 CPUs have long pipelines, so a misprediction requires flushing speculative instructions and refilling from the correct path. Actual cost varies:
- Minimum pipeline refill is often ~10–15 cycles.
- It can be higher (dozens of cycles) if the correct target must come from farther in the cache hierarchy (L2/L3) or due to dependencies/scheduler effects.
- Real-world impact also depends on misprediction rate (modern predictors are very good, but branch-heavy code still suffers).
Mutex Lock/Unlock Latency:
Uncontended Case (userspace atomic operation):
- ~20–60 ns (roughly 60–200+ cycles at 4–5.5 GHz) on modern x86.
- Best case (highly optimized, in-cache atomic): Can be as low as 15–30 ns.
- Realistic average for std::mutex / pthread_mutex (uncontended): 25–50 ns.
Contended Case: Mutex falls back to kernel futex (or equivalent), involving context switches. Key Factors Affecting Latency: Cache state All in L1/L2 → fastest.
P0. 编程原则
1. 首要原则
- Rules with no enforcement are unmanageable for large code bases. 没有强制执行的规则会导致大型代码库无法管理。
- SRP 原则: single responsibility principle 设计原则。比如函数要尽可能简单。
- “事不过三”: 如果你需要超过3级的缩进,那么你已经把事情搞砸了。应该修复你的程序。 if you need more than 3 levels of indentation, you’re screwed anyway, and should fix your program – Linus Torvalds, Linux kernel coding style 经检查,关于多级指针,Linux Kernel源代码只有20多处 两级指针,没有任何的*三级指针。
2. 基本类型或关键字
- 避免裸的Union。因为Union可以规避C++的类型系统,导致不易察觉的bug,因此要避免这样使用。我们可以单独维护一个type field,使它成为一个tagged union;或者,使用C++标准库的variant。
- 如果你的代码有太多cast,说明你已经搞砸了。
- Use
dynamic_castwhere class hierarchy navigation is unavoidable; 当类层次漫游行为不可避免时,使用动态强制转换。 如果无法转换向目标类时,想要它报错,就用dynamic_cast作用于引用类型;不希望报错,就作用于指针类型。 - Use
unique_ptrorshared_ptrto avoid forgetting to delete objects created using new; - new出来的裸指针,直接从函数返回是很危险的。最好用标准库的
unique_ptr,例如return unique_ptr<Shape>{new Circle{p,r}};
2. 函数
- 尽量不要把bool值作为函数参数,而应该是使用枚举类。参见:千万不要把 BOOL设计成函数参数
- 避免使用带有太多内置类型的函数,如: draw_line(int, int, int, int); // obscure。这种代码不容易理解参数类型的含义。
3. 类
C++:
- friend class有利于代码的模块化,它也可用于特定的成员函数。如Node和LinkedList::search()
- 类的设计要合理,make sense, 起码要能从类的名字可推测它可能提供的操作。
- 能用const的地方一定要用const,这会把程序员的意图告诉别人。
- 使用标准库,而不是模仿标准库。( mimics the standard library)
- explicit关键字可以避免代码隐式转换。
- Use concrete classes to represent simple concepts;
- Prefer concerete classes over class hierarchies for performance-critical components; 高性能组件尽可能用具体类
- Make a function a member only if it needs direct access to the representation of a class; 仅当需要直接访问类的表示时,才使用成员函数。
- Declare a member function that does not modify the state of its object
const; - If a class is a container, give it an initializer-list constructor;
- An abstract class typically doesn’t need a constructor;
- A class with a virtual function should have a virtual destructor;
- 由于抽象类灵活的特性,在派生类的destructor函数要保证资源能被释放,这太重要了。
道德指南: 你可以做,但你不应该这样做。
你总是可以写出符合编译器要求的代码,它在语言层面是合法的。但你不应该写出那种代码,因为它不符合道德要求。
现代 C++开发者永远不应该做的事情:
- 永远不要将原始指针用作资源句柄。那样你将违反我所说的所有原则。永远不要通过单个原始指针传递一组元素,比如指向数组的指针。你不知道有多少个元素。你无法进行良好的范围检查。如果你传递一个 vector,它知道有多少个元素,它知道有哪些类型。
- 我几乎不再使用类型转换了,顺便说一句,这是泛型编程的内容。如果你不使用类型转换,你将无法避免很多类型错误。
- 传统上,你从函数中获取大量内容的方式是将某些内容放在自由存储区,动态存储区,然后传递一个指针出来,然后你必须记得稍后删除它。如今你只需将一个 vector 移出即可。这通常是无成本的。
- 优先用import 而不是 include, 使用概念比不使用它们更容易
参考:
1. 面向对象的滥用
classes for separating interfaces from implementations。「类」用于从实现中分离接口。
BS在和Bill Venners的访谈提到:“ 许多C++程序员陷入困境是因为对「面向对象」的滥用,他们认为 C++ 应该是一种非常高级的语言,并且一切都应该是面向对象的。他们认为你应该通过创建一个类作为具有大量虚函数的类层次结构,用这一部分来完成所有工作。例如,这种思想反映在像Java这样的语言中,但很多东西不适合「类」的层次结构。整数(int)不应该是类层次结构的一部分,它不需要,把它放进类里面要开销的;而且很难优雅地做到这一点”[BS03,Bill]。就是说:
- 当你只是需要一个数据结构时,一定不要去把它设计成「类」。如果它真的是一个数据结构,那就让它成为一个数据结构。
- 你不应该计划一个层次结构,因为你不需要。仅当你确实需要一个层次结构时,再去使用继承。
- 你可以用大量独立的「具体类」来编程,比如你想要一个复数,那就写一个复数。不需要用带虚函数的「抽象类」。
优雅的代码 – 审美
Elegance is an attitude – 瑞士手表品牌 浪琴(Longines)
二级指针
示例代码:单向链表中删除一个指定的节点, Linus的做法:代码片段 Linus 的哲学是: 良好的代码应该能够发现并利用底层模式,从而使特殊情况消失,变为普通情况。
{kind=link}
Linus这个代码很妙。我的详细解读:在内存中的一切实体,变量和对象, 都是有地址的,变量当然也包括指针。 所以每个指针实际上有两个地址,第一个是所做指向的对象的地址(即指针的值),另一个则是指针自身的地址,而它自身的地址经常被忽略和遗忘了。 当我们把另一个指针指向该指针的自身地址,那么我们就会得到一个二级指针: 指向指针的指针。
我们为什么需要二级指针?
- 需要一级指针在单步移动,通过比较一级指针的地址而不是比较它所指向的值。
- 需要修改一级指针指向时。
indirect 是一个二级指针,当我们对它进行解引用的时候,我们就会得到一级指针,就这么简单
#include <iostream>
// 定义链表节点
struct Node {
int data;
Node* next;
Node(int d) : data(d), next(nullptr) {}
};
// 全局头指针,方便演示
Node* head = nullptr;
// 辅助函数:向链表末尾添加数据
void append(int data) {
if (!head) {
head = new Node(data);
return;
}
Node* temp = head;
while (temp->next) temp = temp->next;
temp->next = new Node(data);
}
// 辅助函数:打印链表
void print_list() {
Node* temp = head;
while (temp) {
std::cout << temp->data << " -> ";
temp = temp->next;
}
std::cout << "NULL" << std::endl;
}
// 传统的写法 (Poor Taste) ---
void remove_list_entry_poor(Node* entry) {
Node* prev = nullptr;
Node* walk = head;
// 寻找目标节点并记录前驱
while (walk != entry) {
prev = walk;
walk = walk->next;
}
// 必须处理“删除的是头节点”的特殊情况
if (!prev) {
head = entry->next; // 如果没有前驱,说明删除的是第一个
} else {
prev->next = entry->next; // 否则跳过当前节点
}
delete entry; // 释放内存
}
// Linus 推荐的写法 (Good Taste) ---
void remove_list_entry_good(Node* entry) {
// indirect 指向的是“指向当前节点的指针”的地址
Node** indirect = &head;
// 只要当前指向的节点不是目标,就移动到下一个“指针的地址”
while ((*indirect) != entry) {
indirect = &((*indirect)->next); // 多加了括号,更易读
}
// 核心:直接修改那个指向 entry 的指针,让它指向下一个
// 无论是 head 还是某个节点的 next,逻辑完全一致
*indirect = entry->next;
delete entry; // 释放内存
}
int main() {
// 初始化链表: 10 -> 20 -> 30 -> 40 -> NULL
append(10); append(20); append(30); append(40);
std::cout << "原始链表: "; print_list();
// 测试 1: 使用“Good Taste”方法删除中间节点 30
Node* to_remove = head->next->next; // 30
remove_list_entry_good(to_remove);
std::cout << "删除 30 后: "; print_list();
// 测试 2: 使用“Good Taste”方法删除头节点 10 (无特殊处理!)
remove_list_entry_good(head);
std::cout << "删除头节点后: "; print_list();
return 0;
}
C++优先使用指针的引用, 而不是二级指针。
// ❌ 不推荐:二级指针
void func(int** pp) {
*pp = new int(42);
}
int* p;
func(&p);
// ✅ 推荐:引用
void func(int*& p) {
p = new int(42);
}
int* p;
func(p); // 更简洁
C++ 硬实时系统编译
| 编译开关 | 作用 | 目的 |
|---|---|---|
-fno-exceptions |
禁用异常处理 | 消除堆栈回溯带来的时间不确定性 |
-fno-rtti |
禁用运行时类型识别 | 减少二进制文件大小,消除运行时查表开销 |
-O3 / -Ofast |
极致性能优化 | 利用编译器进行循环展开、指令对齐、向量化优化 |
-Wall -Werror |
警告即错误 | 强制执行最高标准的编码规范,消除潜在隐患 |
哲学
异常: On free will and the problem of evil: “I can design a program that never crashes if I don’t give the user any options. And if I allow the user to choose from only a small number of options, limited to things that appear on a menu, I can be sure that nothing anomalous will happen, because each option can be foreseen in advance and its effects can be checked. But if I give the user the ability to write programs that will combine with my own program, all hell might break loose. (In this sense the users of Emacs have much more free will than the users of Microsoft Word.) … I suppose we could even regard Figure 5 (a binary tree representing someone’s choices) as the Tree of the Knowledge of Good and Evil.” (p. 189-190)
C1. 计算机基础
Cache miss延迟的时钟周期
如果 1 CPU 周期 = 1 秒(基于 3 GHz CPU,1 cycle ≈ 0.33 ns),那么各种操作的延迟相当于:
| 操作 | 实际延迟 | 实际时间 | 类比时间 | 生活场景 |
|---|---|---|---|---|
| CPU 寄存器 | 0 cycles | 0 ns | 0 秒 | 脑中回忆 |
| L1 缓存命中 | 4 cycles | 1.3 ns | 4 秒 | 拿起桌上的笔 |
| L2 缓存命中 | 12 cycles | 4 ns | 12 秒 | 从书架取书 |
| L3 缓存命中 | 42 cycles | 14 ns | 42 秒 | 去隔壁房间 |
| 主内存访问 | 200 cycles | 67 ns | 3.3 分钟 | 开车去超市 |
| 分支预测失败 | 20 cycles | 6.7 ns | 20 秒 | 走错路返回 |
| 互斥锁加锁/解锁 | 100 cycles | 33 ns | 1.7 分钟 | 排队等电梯 |
| 系统调用 | 1,500 cycles | 500 ns | 25 分钟 | 开车穿越城市 |
| 上下文切换 | 10,000 cycles | 3 μs | 2.8 小时 | 坐火车去另一个城市 |
| SSD 随机读取 | 50,000 cycles | 16 μs | 14 小时 | 坐飞机跨国旅行 |
| SSD 顺序读取 1MB | 300,000 cycles | 100 μs | 3.5 天 | 一周短途旅行 |
| HDD 寻道时间 | 10,000,000 cycles | 3.3 ms | 4 个月 | 怀孕大半程 |
| 网络:同数据中心 | 1,500,000 cycles | 500 μs | 17 天 | 一个月假期 |
| 网络:跨大陆 | 450,000,000 cycles | 150 ms | 14 年 | 孩子从出生到初中 |
| 网络:地球另一端 | 900,000,000 cycles | 300 ms | 28 年 | 一代人的时间 |
数量级对比:
- 🟢 缓存访问:秒级(可接受)
- 🟡 内存访问:分钟级(开始变慢)
- 🟠 磁盘访问:天/月级(很慢)
- 🔴 网络访问:年级(极慢)
核心启示:程序性能优化的本质是减少”等待时间”,就像人生中尽量减少无效等待一样。
中断
1.这个MCU: Interrupts and Timers幻灯片,开头以没有中断的灯泡切换的程序为例,当针脚的电平改变时无法确定程序刚好能捕捉到这一变化。因为默认的前提是要从时间上保证事件发生的先后顺序,所以需要一个“钟表”保证同步的顺序,这就是中断存在的本质意义。作者讲到中断的自增timer寄存器,它是中断设计的核心。从0增长到最大再回到0,过程独立于CPU。Timer产生两种中断:OVERFLOW interrupt和COMPARE MATCH interrupt,后者依赖是一个OCR(输出比较寄存器),因为它是可编程的,所以我们的操作系统可以指定中断频率。当OCR和timer数值相等,则触发中断。
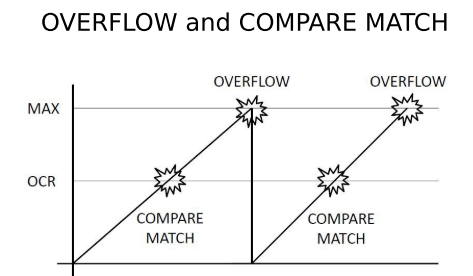
Timer三种模式:a.正常模式,保持自增。b.CTC (Clear Timer on Compare) Mode 比较成功时置零 c.PWM(脉宽调制)模式,利用比较匹配把整个Timer寄存器的数据区间“切分”成两段,分别使用不同电平,由此产生不同宽度脉冲。这一模式在嵌入式上可能得到应用。
CodeVisionAVR可给AVR架构单片机芯片编程。
2.这篇 A Problem of Program Execution Time Measurement论文讨论了程序执行时间测量的误差,误差的根源是因为无法保证测量的开头和结束时间点恰好就是中断的发生时间。在完美理想的情况下,除非中断是连续的,而非间接性的,它才能可能恰如其分的捕捉到事件的开头和结尾。但这就必然会导致程序永远不会被执行,所以这种连续中断的理想不应当成立的。另一方面,自然界不存在真正完美连续的东西,即便是光也是由粒子构成的,这从哲学的角度否定了连续中断存在的可能性。
3.这篇论文Choosing the Right Timer Interrupt Frequency on Linux则测试了各种不同的中断频率,以帮助我们选择最合适的频率。我在这篇文章分别提了Windows和Linux 默认的中断频率数值。
4.CS:APP Beta节选章节 Measuring Program Execution Time,盗版Beta上内容,不知作者为什么在正版上删了很棒的这一章节。CPU在微观上以ns作为事件的时间尺度,而OS在宏观上以ms作为时间尺度。前者基于CPU的时钟自增,后者基于独立的timer. 因此是两种不同的测量方法。由于上下文切换开销大,因此需消除。
一些事件的时间:视频播放,显卡的刷新每33ms;磁盘启动传输大约10ms;OS的任务切换是5-20ms;操作系统管理事件在5千-2万的时钟周期,这个范围的时间尺度是微秒(μs)。
总结:
1.偶然与必然的结合
- 中断信号可以是硬件偶然性事件发出的,比如:keystrokes, disk operations, newwork activity,鼠标移动,这些设备向中断控制器Timer发送IRQ中断请求,接着OS负责切换和调度相应的进程,让用户期望优先的进程完成中断的处理。
- 中断信号也可以由必然性事件产生,因为单有偶然性是不够的,仍需要一个固定周期的时钟来产生中断。它让OS可以“公平”调度多个进程。
2.硬件和软件的统一
所有教材在讲中断时,几乎都没有将硬件和软件两者很好的结合到一起。嵌入式开发则过分关心其电气特性,软件开发则又集中在其软件的抽象层。中断,它既工作在硬件层,又工作在软件层。如果只是关注其中一个特性,必定无法窥见她面纱之下的真实原貌。因此想要了解中断时,就必须要从这两个方面同时把握。从硬件方面,要知道这些硬件存在,这里Timer Interrupt Sources提到了各类的时钟,包括中断时钟PIT、HPET等,其中APIC和TSC是每个CPU都有一个,每个时钟又有不同的区别(Fixed Frequency IRQ,IRQ on terminal count)。从软件方面,理解中断带来的好处。就完成了它的学习。
microsoft: Interrupt Time中断时间仅100纳秒,这个应该不是操作系统调度的Timer Interrupts。因为windows是闭源的,因此无法知道更多。这里有人提到Window是64HZ或100HZ,那么应该是合理的值了。而Linux系统通常是250HZ(4ms),Philip的回答提到了Jiffies值历史上先是100HZ(10ms),后来又改成了1000HZ(1ms)。
2021-10-07
硬实时 vs 软实时
硬实时(Hard Real-Time)和软实时(Soft Real-Time)的区别不在于速度的“快慢”,而在于对确定性(Determinism)和后果(Consequences)**的要求。
- 对“截止时间”(Deadline)的容忍度
这是两者最本质的区别。在实时系统中,一个任务不仅要计算正确,还要在规定时间内完成。
- 硬实时:截止时间是绝对的。如果任务晚了一毫秒,就被视为系统故障(System Failure)。就像在 Stroustrup论文 Abstraction and the C++ machine model 中看到的船舶引擎控制,如果喷油指令晚了,可能会导致物理损坏。
- 软实时:截止时间是期望的。如果任务偶尔晚了一点,系统性能会下降(比如视频掉帧),但系统依然可以继续运行,不会发生灾难。
- 典型应用场景对比
| 特性 | 硬实时 (Hard Real-Time) | 软实时 (Soft Real-Time) |
|---|---|---|
| 违约后果 | 灾难性(人员伤亡、昂贵设备损坏) | 体验下降(不爽、卡顿、重试) |
| 典型例子 | 汽车安全气囊、起搏器、飞控系统 | 视频会议、在线游戏、自动贩卖机 |
| 成功标准 | 100% 确定性完成(零容忍) | 统计学上的平均完成时间 |
| OS 调度 | 抢占式、优先级严格固定 | 尽力而为 (Best Effort) |
| 时间约束 | 截止时间(Deadline)是硬指标 | 截止时间是目标,允许偶尔偏离 |
- 技术实现上的挑战
硬实时的“禁区”。在硬实时编程中,你必须避开所有执行时间不确定的操作:
- 动态内存分配:new 和 delete 可能会触发内存碎片整理,耗时无法预测。
- 异常处理 (throw/catch):正如你刚才引用的,堆栈回溯的时间取决于调用深度,难以预测。
- 垃圾回收 (GC):像 Java/Python 这种有自动 GC 的语言很难用于硬实时,因为你不知道 GC 什么时候会突然“停顿世界”。
软实时的“宽容”:在软实时系统中,你可以使用 std::vector 的动态扩容,也可以偶尔处理异常。虽然这些会带来波动,但只要平均延迟(Latency)足够低,用户就不会察觉。
- 为什么 Stroustrup 对“确定性”(Predictability 可预测性)如此执着?
Stroustrup 讨论 dynamic_cast 的优化(质数取模法)以及异常的可预测性,本质上都是为了把 C++ 推进硬实时领域。他希望 C++ 程序员能够写出:
- 逻辑上正确的代码。
- 时间上可预测的代码。
如果 dynamic_cast 消耗的时间取决于继承树的深度,那么它就是“不确定”的,也就无法用于控制火星探测器的降落伞开启。Stroustrup 在论文里对异常处理(Exceptions)和动态分配(Memory Allocation)表现得如此谨慎——因为在船舶引擎或火星车(Mars Rover,论文第 1 页提到)这样的系统中,一次延迟就意味着整个物理系统的彻底终结。
- 性能建议: 禁用异常,禁用rtti
- 空间开销:开启 RTTI 会增加可执行文件的大小(因为要存储类型字符串和继承关系表)。
- 时间开销:dynamic_cast 比普通转换慢得多。
- 现代做法:在很多高性能或嵌入式领域(如游戏引擎、底层驱动),开发者常通过编译器选项(如 -fno-rtti)彻底禁用 RTTI,转而使用手动定义的 enum 或模板技术(如 std::variant)来替代。
在目前的硬实时工业界(如汽车自动驾驶、卫星控制),最主流的做法依然是禁用异常(使用编译选项 -fno-exceptions)。这正是 Stroustrup 在论文中提到的“传统错误处理策略”的现代化延续。
P3. 性能优化
避免Cache miss的方法
1.数据局部性: 跳跃访问 → 顺序访问
// ❌ 坏:跳跃访问
for (int i = 0; i < N; i++) {
sum += arr[i * 1000]; // 可能每次都 miss
}
// ✅ 好:顺序访问
for (int i = 0; i < N; i++) {
sum += arr[i]; // 利用预取
}
2. 数据结构重排(AoS → SoA)
结构体放在数组 vs 数组放在结构体
// ❌ Array of Structures (AoS)
struct Point {
float x, y, z;
int id;
char name[32];
};
Point points[1000];
// 只访问 x 坐标,但加载了整个结构
for (int i = 0; i < 1000; i++) {
sum += points[i].x; // 浪费缓存
}
// ✅ Structure of Arrays (SoA)
struct Points {
float x[1000];
float y[1000];
float z[1000];
// ...
};
Points points;
// 紧密排列,缓存友好
for (int i = 0; i < 1000; i++) {
sum += points.x[i]; // 高效!
}
3. 预取(Prefetch)- SSE指令集
#include <xmmintrin.h>
for (int i = 0; i < N; i++) {
// 提前加载下一次迭代的数据,_MM_HINT_T0表示所有级别的缓存(L1, L2, L3)
_mm_prefetch(&arr[i + 8], _MM_HINT_T0);
process(arr[i]);
}
典型用法: 常用的场景是在遍历大型数组或链表时,在处理当前元素的同时,预取后面若干个元素。
避坑:
- 不要过度预取:预取本身是一条指令,会消耗执行资源。如果数据已经在缓存中,预取指令就是纯粹的浪费。
- 找准“预取距离”:预取太晚,数据还没到 CPU 就已经运行到那行了;预取太早,数据可能会在被使用前就被踢出缓存。通常设置为未来 2-4 个缓存行(约 128-256 字节)的位置。
- 对齐要求:_mm_prefetch 对地址对齐没有强制要求(它不会触发页面错误或分段错误),即使传入非法地址,CPU 也会直接忽略该指令。
- 计算密集型 vs 内存密集型:如果你的循环已经是计算密集的(CPU 忙得不可开交),预取可能无法提升性能;它主要用于内存受限(Memory-bound)的场景。
4. 缓存对齐
// ✅ 对齐到缓存行
alignas(64) struct Data {
int value;
};
5. 分块处理(Blocking/Tiling)
缓存对齐: 多核并发的伪共享问题
现代 CPU 以缓存行(Cache Line)为单位加载数据:
- 典型大小64 字节(也可能是 32、128 字节)
- 即使只访问 1 字节,CPU 也会加载整个缓存行
两个线程分别访问不同的变量,但这些变量在同一个缓存行中。
struct Data {
int counter1; // 线程1 修改
int counter2; // 线程2 修改
};
Data data;
// 线程1
void thread1() {
for (int i = 0; i < 1000000; i++) {
data.counter1++; // 修改 counter1
}
}
// 线程2
void thread2() {
for (int i = 0; i < 1000000; i++) {
data.counter2++; // 修改 counter2
}
}
问题:
counter1和counter2在同一缓存行- 线程1 修改
counter1→ 整个缓存行失效 - 线程2 的缓存行失效 → 需要重新加载
- 线程2 修改
counter2→ 线程1 的缓存行又失效 - 不停地缓存失效和重新加载 → 性能暴降
无伪共享(Good):
缓存行1(64字节)
┌────────────────────────────────────────┐
│ counter1 │ … padding … │
│ (4B) │ │
└────────────────────────────────────────┘
↑
线程1
缓存行2(64字节)
┌────────────────────────────────────────┐
│ counter2 │ … padding … │
│ (4B) │ │
└────────────────────────────────────────┘
↑
线程2
两个线程独立的缓存行,互不干扰!
解决方案:缓存对齐
方法 1: alignas 关键字(C++11)
#include <iostream>
#include <thread>
#include <chrono>
// ❌ 无对齐(有伪共享)
struct NoAlignment {
int counter1;
int counter2;
};
// ✅ 有对齐(无伪共享)
struct WithAlignment {
alignas(64) int counter1;
alignas(64) int counter2;
};
template<typename T>
void benchmark(const char* name) {
T data{};
auto thread1 = [&]() {
for (int i = 0; i < 100000000; i++) {
data.counter1++;
}
};
auto thread2 = [&]() {
for (int i = 0; i < 100000000; i++) {
data.counter2++;
}
};
auto start = std::chrono::high_resolution_clock::now();
std::thread t1(thread1);
std::thread t2(thread2);
t1.join();
t2.join();
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << name << ": " << duration.count() << " ms\n";
}
int main() {
benchmark<NoAlignment>("无对齐(伪共享)");
benchmark<WithAlignment>("有对齐(无伪共享)");
}
典型输出(双核系统):
无对齐(伪共享): 2500 ms
有对齐(无伪共享): 800 ms
性能提升:约 3 倍!
方法 2:手动填充(Padding)
struct PaddedCounter {
int value;
char padding[60]; // 4 + 60 = 64 字节
};
struct Data {
PaddedCounter counter1;
PaddedCounter counter2;
};
方法 3: alignas + hardware_destructive_interference_size
#include <new> // C++17
struct Counter {
alignas(std::hardware_destructive_interference_size) int value;
};
- hardware_destructive_interference_size:避免伪共享的最小对齐大小
- hardware_constructive_interference_size:促进共享的最大对齐大小
实际应用场景
场景 1:多线程计数器
#include <atomic>
// ❌ 错误:所有计数器在同一缓存行
struct BadCounters {
std::atomic<int> thread1_count;
std::atomic<int> thread2_count;
std::atomic<int> thread3_count;
std::atomic<int> thread4_count;
};
// ✅ 正确:每个计数器独占缓存行
struct GoodCounters {
alignas(64) std::atomic<int> thread1_count;
alignas(64) std::atomic<int> thread2_count;
alignas(64) std::atomic<int> thread3_count;
alignas(64) std::atomic<int> thread4_count;
};
场景 2:生产者-消费者队列
template<typename T>
class LockFreeQueue {
// ✅ 头尾指针分别对齐,避免伪共享
alignas(64) std::atomic<size_t> head_;
alignas(64) std::atomic<size_t> tail_;
std::vector<T> buffer_;
};
场景 3:线程局部数据
struct ThreadLocalData {
alignas(64) int processed_count;
alignas(64) int error_count;
alignas(64) double total_time;
};
// 每个线程一个实例
std::vector<ThreadLocalData> thread_data(num_threads);
场景 3:线程局部数据
struct ThreadLocalData {
alignas(64) int processed_count;
alignas(64) int error_count;
alignas(64) double total_time;
};
// 每个线程一个实例
std::vector<ThreadLocalData> thread_data(num_threads);
场景 4:读写分离
struct ThreadLocalData {
alignas(64) int processed_count;
alignas(64) int error_count;
alignas(64) double total_time;
};
// 每个线程一个实例
std::vector<ThreadLocalData> thread_data(num_threads);
数据性能: 数组 > 链表(内存池) > 链表(传统)
class NodePool {
static constexpr size_t POOL_SIZE = 1000;
Node nodes[POOL_SIZE];
size_t next_index = 0;
public:
Node* allocate(int data) {
if (next_index >= POOL_SIZE) {
throw std::bad_alloc();
}
Node* node = &nodes[next_index++];
node->data = data;
node->next = nullptr;
return node;
}
};
// 使用内存池
NodePool pool;
Node* n1 = pool.allocate(1); // 在 pool 中连续分配
Node* n2 = pool.allocate(2);
Node* n3 = pool.allocate(3);
// 使用时仍然是链表的操作方式
Node* head = pool.allocate(1);
head->next = pool.allocate(2);
head->next->next = pool.allocate(3)
// 遍历仍然是链表方式
Node* current = head;
while (current != nullptr) {
std::cout << current->data;
current = current->next; // ← 仍然用指针链接
}
效果:
Pool 内存(连续):
地址 内容
------ --------
0x2000 [1][next]
0x2010 [2][next]
0x2020 [3][next]
访存更连续,缓存命中率提高!
内存池的核心思想:用数组来存储链表节点,获得数组的内存连续性优势。
// 传统链表:每个节点单独 new,分散在堆上
Node* n1 = new Node(1); // 可能在 0x1000
Node* n2 = new Node(2); // 可能在 0x5A00
Node* n3 = new Node(3); // 可能在 0x2B00
// 内存池:节点存储在连续的数组中
Node nodes[1000]; // 连续内存:0x2000-0x5000
Node* n1 = &nodes[0]; // 在 0x2000
Node* n2 = &nodes[1]; // 在 0x2010(连续!)
Node* n3 = &nodes[2]; // 在 0x2020(连续!)
内存池快 7 倍左右, 预取有效。
循环展开
减少循环迭代的次数,并在每一次循环中多做几次重复的工作。
普通循环
for (int i = 0; i < 100; i++) {
box[i] = apple[i];
}
循环展开(展开因子为 4)
for (int i = 0; i < 100; i += 4) {
box[i] = apple[i];
box[i + 1] = apple[i + 1];
box[i + 2] = apple[i + 2];
box[i + 3] = apple[i + 3];
}
1.循环展开的好处。在底层 CPU 执行时,循环展开能显著提升性能,原因有三:
- 减少管理开销:减少了循环变量(如 i++)的自增次数,以及判断循环是否结束(如 i < 100)的比较跳转指令。
- 提升“指令级并行”(ILP): 现代 CPU 像流水线工厂。如果一次循环里只有一行代码,流水线还没跑起来就得等下一次循环。展开后,CPU 发现这 4 行搬苹果的代码互不干扰,可以同时启动 4 个“机械臂”一起搬。
- 减少分支预测失败:CPU 总是预判你会继续循环。每多一次跳转,预判出错的概率就多一分。展开减少了跳转次数,也就让 CPU 跑得更顺。
2.展开的“代价”(副作用)。虽然跑得快,但不是展开得越多越好:
- 代码膨胀(Code Bloat):二进制文件会变大。如果代码大到 CPU 的指令缓存(Instruction Cache)装不下了,反而会因为频繁去内存读取指令而导致严重掉速。
- 寄存器压力:如果一次循环里处理的任务太多,CPU 的寄存器(最快的临时存储空间)不够用了,就得把数据写回较慢的内存,适得其反。
3.谁来做这件事?
- 编译器:这是最推荐的方式。像 GCC 或 Clang 编译器在 -O2 或 -O3 优化级别下,会自动根据你的 CPU 类型判断是否该展开。
- 手动展开:在极端高性能需求下(如你 JSF++ 航天代码或 自动驾驶 FSD),程序员有时会手动展开,或者使用
#pragma unroll指令告诉编译器:“听我的,这里必须展开”。
内联(Inlining)
把函数调用的指令,直接替换为函数体内的具体代码。
- 目的是消除函数调用的开销,省去了参数传递、保存寄存器、指令跳转和返回的时间。对于只有一两行代码的小函数,调用它的开销往往比执行它的时间还长。
- 触发进一步优化:内联后,原本分散在两个函数里的代码“连在了一起”。编译器现在能看到全局,可能会发现 a * a 里的 a 是常量 5,从而直接把结果预计算为 25(这叫常量折叠)。
- 对指令流水线友好:CPU 喜欢直线行驶。内联消除了“弯道”(跳转指令),让 CPU 的分支预测器跑得更稳,流水线更高效。
内联的“代价”(副作用):
- 代码膨胀(Code Bloat):如果一个很大的函数在 100 个地方被内联,你的程序体积会迅速爆炸。
- 缓存失效率(Cache Miss):如果二进制文件太大,超出了 CPU 的指令缓存(L1 i-Cache),CPU 就得从慢速的内存里读取指令,性能反而会断崖式下跌。
程序员如何控制内联?
- inline 关键字:这只是给编译器的一个“建议”。编译器很聪明,如果你建议内联一个 1000 行的复杂函数,它通常会拒绝。
- 编译器自动优化:在 -O2 或 -O3 级别下,编译器会自动分析哪些函数值得内联(通常是那些逻辑简单、频繁调用的函数)。
- 强制内联:在某些严苛场景下,程序员会使用 attribute((always_inline))(GCC/Clang)来命令编译器必须执行内联。
Golang的性能优化
原则:先测量,后优化
- Diagnostics - Go Doc
- Profiling Go Programs - Go Blog (展示如何具体的Profiling)
在 Golang 中,性能调优通常遵循 “先测量,后优化” 的原则, 找到程序瓶颈。过度优化(Premature Optimization)是万恶之源。作为一名 C++ 背景的开发者,Go 很多调优技巧实际上是在“对抗”垃圾回收(GC)和内存分配器的开销。
- runtime/pprof: Go 标准库内置的杀手锏。通过 net/http/pprof 可以实时查看 CPU 耗时、内存分配(Heap)和协程(Goroutine)状态。性能分析工具分析 Go 程序的复杂性和成本,例如内存使用情况和频繁调用的函数,以识别 Go 程序中成本高昂的部分。
- Debugging: Delve, Go 程序的全面且可靠的调试器。
- Benchmark: 编写基准测试,使用 go test -bench . -benchmem 查看单次操作耗时和内存分配次数。
某些诊断工具可能会相互干扰。例如,精确的内存分析会扭曲 CPU 分析,goroutine 阻塞分析会影响调度器跟踪。单独使用工具以获取更精确的信息。
- 别的分析器: 在 Linux 上,可以使用 perf 工具来分析 Go 程序。 Perf 可以分析并展开 cgo/SWIG 代码和内核,因此它对于了解原生/内核性能瓶颈很有用。在 macOS 上,可以使用 Instruments 套件来分析 Go 程序。
- 分析我生产服务:你可能需要定期分析你的生产服务。特别是在一个有多个单个进程副本的系统中,定期随机选择一个副本是一个安全的选项。
- 可视化分析数据: Go 工具使用 go tool pprof 提供文本、图形和 callgrind 分析数据的可视化。图形形式: weblist 形式, Flame graphs
记住:先写清晰正确的代码,用 profiler 找到真正的瓶颈,然后才针对性优化!
性能测试命令:
# CPU 性能分析
go run havlak6.go -cpuprofile=cpu.prof
# 内存分析
go run havlak6.go -memprofile=mem.prof
# 查看分析结果
go tool pprof cpu.prof
go tool pprof mem.prof
逃逸分析:
# 查看哪些变量逃逸到堆
go build -gcflags="-m" havlak6.go
当Go程序员注意内部循环生成的垃圾数量时,Go的性能可以与同等优化的C++程序相媲美。
目标: 减少 GC压力 和 内存分配
Go 的性能瓶颈往往不在 CPU,而是在内存分配导致的 GC 压力。
原因:
- 频繁分配内存: make 会在堆(Heap)上请求内存。如果 nodes 很大,这会发生数百万次。
- GC 回收的压力: 每次循环结束,这些局部切片就变成了垃圾。Go 的垃圾回收器(GC)必须跟踪、扫描并清理这些成千上万的小对象,导致大量的 CPU 时间被浪费在回收内存上,而不是运行业务逻辑。
检查清单和实践建议
编写高性能 Go 代码时,问自己:
- 这个对象能复用吗? 而不是每次新建。
- 这个切片能预分配容量吗?
- 能用数组/切片代替 map 吗?
- 能用值类型代替指针吗?
- 这个 getter 方法必要吗?
- 数据结构能更紧凑吗?
- 能减少间接访问吗?
- 这段代码是热路径吗?(经常执行)
- 逃逸分析显示有哪些变量逃逸了?
- 能用值类型代替指针吗?
- 能用 sync.Pool 吗?
- 优化后性能提升了多少?(用基准测试验证)
复用、清空,而不是重新分配内存。
- 关注 make 的位置: 永远问自己,这个 make 能不能挪到for循环的外面?
- 切片清空和复用,而不是重分配内存。可以使用 slice[:0] 来清空内容,但这保留了底层的 Capacity (容量),从而避免了重新分配内存。
- 考虑 Sync.Pool: 如果你的函数会被多个 Goroutine 并发调用,且需要复用大型结构体或缓冲区,sync.Pool 是进阶必备工具。
初级:
- 先写正确的代码,再优化
- 使用 go test -bench 进行基准测试
- 使用 pprof 找到真正的性能瓶颈
- 一次优化一个点,对比结果
中级:
- 养成预分配切片容量的习惯
- 在合适的地方使用对象池
- 理解值类型和指针的权衡
- 学习使用 escape analysis 工具
优化案例:
func FindLoops(cfgraph *CFG, lsgraph *LSG) {
if cfgraph.Start == nil {
return
}
size := cfgraph.NumNodes()
nonBackPreds := make([]map[int]bool, size)
backPreds := make([][]int, size)
number := make(map[*BasicBlock]int)
header := make([]int, size, size)
types := make([]int, size, size)
last := make([]int, size, size)
nodes := make([]*UnionFindNode, size, size)
// Bad: 每一轮循环都重新分配内存
for i := 0; i < size; i++ {
nodes[i] = new(UnionFindNode)
}
// ...
}
在原始代码, 由于基准测试调用 FindLoops 50次,这些累积起来会形成大量垃圾,因此需要垃圾收集器进行大量工作。拥有垃圾回收语言并不意味着可以忽视内存分配问题。在这种情况下,一个简单的解决方案是引入缓存,以便在可能的情况下,每次调用 FindLoops 时都能重用前一次调用的存储空间。
Pre-allocation & Reuse(预分配与复用) 优化方案1:
// 全局的cache结构 (bad engineering practice, 并发不安全)
var cache struct {
size int
nonBackPreds [][]int
backPreds [][]int
number []int
header []int
types []int
last []int
nodes []*UnionFindNode
}
if cache.size < size {
cache.size = size
cache.nonBackPreds = make([][]int, size)
cache.backPreds = make([][]int, size)
cache.number = make([]int, size)
cache.header = make([]int, size)
cache.types = make([]int, size)
cache.last = make([]int, size)
cache.nodes = make([]*UnionFindNode, size)
for i := range cache.nodes {
cache.nodes[i] = new(UnionFindNode)
}
}
nonBackPreds := cache.nonBackPreds[:size]
for i := range nonBackPreds {
nonBackPreds[i] = nonBackPreds[i][:0]
}
backPreds := cache.backPreds[:size]
for i := range nonBackPreds {
backPreds[i] = backPreds[i][:0]
}
number := cache.number[:size]
header := cache.header[:size]
types := cache.types[:size]
last := cache.last[:size]
nodes := cache.nodes[:size]
在 Russ Cox (rsc) 的这个代码提交中,优化的核心思想是:
- 提升作用域,避免重新内存分配。与其在循环里反复创建和销毁,不如全局的方式创建,然后在循环里重复使用。
- 使用 slice[:0] 来清空内容,但这保留了底层的 Capacity (容量),从而避免了重新分配内存。
Pre-allocation & Reuse(预分配与复用) 最终优化方案:
最终的 Go 程序将使用一个单独的 LoopFinder 实例来跟踪这段内存,从而恢复并发使用的可能性
数据结构: 切片替代Map集合, 提升缓存局部性
程序员的需求: 想要一个支持高性能遍历的、无重复的集合,应该用切片。
切片替代集合(不需要map的值)
// havlak1.go 中的做法, Bad
type SimpleLoop struct {
basicBlocks map[*BasicBlock]bool // map 开销大
Children map[*SimpleLoop]bool
// ...
}
func (loop *SimpleLoop) AddNode(bb *BasicBlock) {
loop.basicBlocks[bb] = true
}
// havlak6.go 中的做法, Good
type Loop struct {
Block []*Block // 切片比 map 更高效
Child []*Loop
Parent *Loop
Head *Block
// ...
}
// 直接添加到切片
l.Block = append(l.Block, w.Block)
痛点: Go 的 Map 是哈希表。即使 Key 是整数,每次查找也需要计算哈希、桶扫描。而且 Map 的内存是分散的,对 CPU 缓存(Cache)非常不友好。
优化:
- Map vs Slice:当不需要快速查找时,切片比 map 更高效。
- 缓存友好:切片在内存中连续存储,缓存命中率更高
- 减少堆分配:map 涉及更多的堆分配和指针跳转
“去重 + 高频遍历”:双结构维护(keys []T + set map[T]struct{})
type UniqueList[T comparable] struct {
keys []T // 用于高效遍历(保持插入顺序)
set map[T]struct{} // 用于 O(1) 去重
}
func NewUniqueList[T comparable]() *UniqueList[T] {
return &UniqueList[T]{
keys: make([]T, 0),
set: make(map[T]struct{}),
}
}
// Add 添加元素(自动去重)
func (ul *UniqueList[T]) Add(item T) {
if _, exists := ul.set[item]; !exists {
ul.set[item] = struct{}{}
ul.keys = append(ul.keys, item)
}
}
// Contains 快速检查是否存在
func (ul *UniqueList[T]) Contains(item T) bool {
_, exists := ul.set[item]
return exists
}
// Range 高效遍历(缓存友好!)
func (ul *UniqueList[T]) Range(fn func(T)) {
for _, item := range ul.keys {
fn(item)
}
}
// Len 返回元素个数
func (ul *UniqueList[T]) Len() int {
return len(ul.keys)
}
数据结构: 切片+索引,替代key连续整数的Map,消除哈希计算
如果你的 Key 是连续整数,永远优先使用 Slice 而不是 Map。 Slice 的 O(1) 随机访问通过简单的指针偏移完成,且内存分布是连续的,对 CPU 缓存极其友好。
number := make(map[*BasicBlock]int) // map 需要哈希计算, Bad
func DFS(currentNode *BasicBlock, nodes []*UnionFindNode,
number map[*BasicBlock]int, last []int, current int) int {
number[currentNode] = current
// ...
for _, target := range currentNode.OutEdges {
if number[target] == unvisited {
lastid = DFS(target, nodes, number, last, lastid+1)
}
}
}
// 好的做法
type LoopFinder struct {
LoopBlock []LoopBlock // 注意:这是一个 **切片(slice)**,不是 map!
DepthFirst []*LoopBlock
}
type LoopBlock struct {
Block *Block
First int
Last int
// ...
}
type Block struct {
Name int
In []*Block
Out []*Block
}
func (f *LoopFinder) Search(b *Block) {
lb := &f.LoopBlock[b.Name] // b.Name是整数ID,数组索引,O(1) 且无哈希
f.DepthFirst = append(f.DepthFirst, lb)
lb.First = len(f.DepthFirst)
for _, out := range b.Out {
if f.LoopBlock[out.Name].First == Unvisited {
f.Search(out)
}
}
lb.Last = len(f.DepthFirst)
}
这种优化能成立,依赖两个关键假设:
- 基本块 ID 是连续整数(0 ~ N-1)→ 可以直接用作数组索引
- 总块数已知且固定 可预先分配 make([]LoopBlock, N)(无需动态扩容)
消除不必要的内存分配: make一次完成内存分配,多次复用
需要某个对象,不要每次都重新分配,重新初始化已有对象。
// havlak1.go - 每次都分配新对象, Bad
func FindLoops(cfgraph *CFG, lsgraph *LSG) {
size := cfgraph.NumNodes()
// 每次都重新分配这些数据结构
nonBackPreds := make([]map[int]bool, size)
backPreds := make([][]int, size)
number := make(map[*BasicBlock]int)
header := make([]int, size, size)
types := make([]int, size, size)
last := make([]int, size, size)
nodes := make([]*UnionFindNode, size, size)
for i := 0; i < size; i++ {
nodes[i] = new(UnionFindNode) // 每次创建新对象
}
for i, bb := range cfgraph.Blocks {
nonBackPreds[i] = make(map[int]bool) // 每次创建新 map
}
}
// havlak6.go - 复用已分配的内存, Bad
type LoopFinder struct {
LoopBlock []LoopBlock // 可复用的块数组
DepthFirst []*LoopBlock // 可复用的指针切片
Pool []*LoopBlock // 可复用的工作池
}
func (lb *LoopBlock) Init(b *Block) {
lb.Block = b
lb.Loop = nil
lb.First = Unvisited
lb.Last = Unvisited
lb.Header = nil
lb.Type = bbNonHeader
lb.BackPred = lb.BackPred[:0]
lb.NonBackPred = lb.NonBackPred[:0]
lb.Union = lb
}
func (f *LoopFinder) FindLoops(g *CFG, lsg *LoopGraph) {
size := len(g.Block)
// 复用现有容量,避免重新分配
if size <= cap(f.LoopBlock) {
f.LoopBlock = f.LoopBlock[:size]
f.DepthFirst = f.DepthFirst[:0]
} else {
f.LoopBlock = make([]LoopBlock, size)
f.DepthFirst = make([]*LoopBlock, 0, size)
}
// 重新初始化已有对象,而不是创建新对象
for i := range f.LoopBlock {
f.LoopBlock[i].Init(g.Block[i])
}
}
- 对象池模式:将 LoopFinder 设计为可复用的结构体
- 切片复用:通过 slice[:0] 清空切片但保留底层数组
- 容量检查:if size <= cap(…) 判断是否需要重新分配
- 就地初始化:用 Init() 方法重置对象状态,而不是创建新对象
// ❌ havlak1.go - 每次创建新的循环图
func main() {
for i := 0; i < 50; i++ {
FindHavlakLoops(cfgraph, NewLSG()) // 每次创建新 LSG, Bad
}
}
func (lsg *LSG) NewLoop() *SimpleLoop {
loop := new(SimpleLoop)
loop.basicBlocks = make(map[*BasicBlock]bool) // 新 map
loop.Children = make(map[*SimpleLoop]bool) // 新 map
// ...
return loop
}
// ✅ havlak6.go - 清空并复用循环图
func main() {
lsg := new(LoopGraph)
for i := 0; i < 50; i++ {
if *reuseLoopGraph {
lsg.Clear() // 清空而不是丢弃
f.FindLoops(g, lsg)
} else {
f.FindLoops(g, new(LoopGraph))
}
}
}
func (g *LoopGraph) Clear() {
g.Root.Child = g.Root.Child[:0] // 清空但保留容量
g.Loop = g.Loop[:0] // 清空但保留容量
}
func (g *LoopGraph) NewLoop(lcap int) *Loop {
// 检查是否有缓存的循环可以复用
if n := len(g.Loop); n < cap(g.Loop) && g.Loop[:n+1][n] != nil {
g.Loop = g.Loop[:n+1]
l := g.Loop[n]
// 重置已有对象的状态
l.Block = l.Block[:0]
l.Child = l.Child[:0]
l.Parent = nil
l.Head = nil
l.IsRoot = false
l.IsReducible = false
l.Nesting = 0
l.Depth = 0
return l
}
// 只有在必要时才创建新对象
loopCounter++
l := &Loop{Counter: loopCounter}
g.Loop = append(g.Loop, l)
l.Block = make([]*Block, 0, lcap)
return l
}
- 智能对象复用:检查 cap(g.Loop) 来判断是否有预分配的对象
- 部分重置:只重置需要清空的字段
- 延迟分配:只在真正需要时才分配新对象
- 预分配容量:make([]*Block, 0, lcap) 预留容量减少后续扩容。空间换时间。
使用对象池
type Buffer struct {
data []byte
}
var bufferPool = sync.Pool{
//
New: func() interface{} {
return &Buffer{
data: make([]byte, 0, 1024),
}
},
}
// ❌ 每次都创建新 buffer
func processWithoutPool(input []byte) []byte {
buf := &Buffer{data: make([]byte, 0, len(input))} // 逃逸
buf.data = append(buf.data, input...)
// 处理 buf.data
return buf.data
}
// ✅ 使用对象池
func processWithPool(input []byte) []byte {
// 从池中“借”对象(Get), 如果池中有空闲对象,返回它; 如果池为空,New 创建新对象
buf := bufferPool.Get().(*Buffer)
// 用完“归还”到池(Put)
defer bufferPool.Put(buf)
buf.data = buf.data[:0] // 清空但保留容量
buf.data = append(buf.data, input...)
// 处理 buf.data
// 注意:返回的数据需要拷贝,因为 buffer 会被放回池中
result := make([]byte, len(buf.data))
copy(result, buf.data)
return result
}
结构体内联与紧凑设计
// ❌ havlak1.go - 分离的数据结构, 需要多个独立的数据结构
nonBackPreds := make([]map[int]bool, size)
backPreds := make([][]int, size)
nodes := make([]*UnionFindNode, size)
type UnionFindNode struct {
parent *UnionFindNode // 指针,额外间接访问
bb *BasicBlock
loop *SimpleLoop
dfsNumber int
}
// ✅ havlak6.go - 紧凑的结构体
type LoopBlock struct {
Block *Block
Loop *Loop
First int
Last int
Header *LoopBlock
Type LoopType
BackPred []*LoopBlock // 切片直接内联
NonBackPred []*LoopBlock
Union *LoopBlock
}
// 所有数据在一个数组中
f.LoopBlock = make([]LoopBlock, size)
- 值类型数组:[]LoopBlock 而非 []*LoopBlock,减少指针跳转
- 字段合并:把相关数据合并到一个结构体
- 内存布局:连续的内存布局提升缓存性能
切片的容量预分配和复用
// ❌ havlak1.go - 未预分配容量
var nodePool []*UnionFindNode // 容量为 0,会多次扩容
for _, pred := range w.BackPred {
// ...
nodePool = append(nodePool, pred.Find()) // 可能触发扩容
}
// ✅ havlak6.go - 预分配+复用
pool := f.Pool[:0] // 复用已有容量
for _, pred := range w.BackPred {
// ...
pool = append(pool, pred.Find())
}
f.Pool = pool // 保存供下次复用
- 容量复用:[:0] 清空但保留容量
- 减少扩容:预分配避免多次内存重新分配
- 状态保存:把工作切片保存在结构体中
消除不必要的函数调用, 直接访问字段
// ❌ havlak1.go - 值拷贝
func (bb *BasicBlock) NumPred() int {
return len(bb.InEdges)
}
func (bb *BasicBlock) NumSucc() int {
return len(bb.OutEdges)
}
// havlak6.go - 去除不必要的方法, 直接访问字段
len(b.In)
len(b.Out)
- 简单字段访问:不需要为简单的字段包装 getter
- 减少函数调用开销:直接访问更高效
- Go 惯例:Go 推荐直接访问公开字段
预分配内存: 对于可变容量的数据结构,在初始化 Slice 或 Map 时,如果预知容量,应提供容量信息,避免多次重新分配内存和复制元素。例如:
- 切片 make([]T, 0, capacity),
- Map: make(map[K]V, hint)。
其他
- 减少变量逃逸: 尽量将变量限制在栈上,避免对象逃逸到堆上,从而降低 GC 压力。
- 使用空结构体: 使用 struct{} 作为占位符不占用内存,常用于实现高效的 Set,如 map[string]struct{}。
-
字符串处理。使用 strings.Builder 拼接大量字符串,避免 + 拼接带来的频繁内存分配。
-
并发与锁优化原子操作: 使用 sync/atomic 包代替简单的 sync.Mutex 锁,以获得指令级的性能提升。
4.数据结构优化:结构体内存对齐, 按照字段字节大小由大到小排序合理设计结构体布局,可减少内存占用。
5.工具与方法论
- pprof: 使用 net/http/pprof 分析 CPU、内存占用情况,定位热点函数,关注 gcBgMarkWorker 等 GC 相关的 CPU 消耗。
- 火焰图: 直观定位函数调用栈中的性能瓶颈。
- 压测先行: 针对热点逻辑编写 Benchmark 用例,确保优化有效
C++的缺陷与性能优化
C++的机器模型的缺陷
C++ 中没有任何东西可以方便地表达二级缓存(2nd level cache)、内存映射单元(memory-mapping unit)、ROM 或专用寄存器的概念。这些概念很难抽象(以有用且可移植的方式表达),但标准库组件正在努力表达这种困难的设施。
对二级缓存(L2 Cache / Cache Line)的表达
C++ 无法直接让你控制数据进出 L2 缓存,但它开始尝试让你表达 “缓存对齐” 以避免伪共享(False Sharing)。
std::hardware_destructive_interference_size (C++17): 这是一个标准库常量,返回两个对象之间为了避免由于共享同一个缓存行(Cache Line)而导致性能下降所需的最小偏移量。
std::hardware_constructive_interference_size (C++17): 返回一个缓存行的最大尺寸,建议将相关联的数据放在这个范围内,以提高 L1/L2 缓存的利用率。
对内存映射单元(MMU)与页面的表达 C++ 不会教你如何写一个 MMU 驱动,但它开始涉及内存页面的概念:
std::pmr (Polymorphic Memory Resources): C++17 引入的自定义内存资源。你可以实现一个自定义的 memory_resource,专门处理内存映射(Memory-mapping)或大页内存(Huge Pages),从而间接与 MMU 的行为对齐。
span 与内存连续性: 虽然不是直接操作页表,但标准库通过 std::span 等工具强化了对底层连续物理/虚拟内存段的抽象表达。
对专用寄存器与 ROM 的表达 这些通常是嵌入式开发的刚需,标准库主要通过类型系统来模拟这些特性:
volatile 关键字: 虽然属于核心语言,但它是表达专用寄存器映射(Memory-mapped I/O)的基础,告诉编译器“这个值随时会变,不要做优化”。
std::byte (C++17): 明确区分“内存字节”和“字符”,在操作寄存器位(bit-flipping)时比 unsigned char 更安全且意图明确。
const 与 constexpr: 这是表达 ROM 的主要手段。在嵌入式系统中,标记为 constexpr 的全局数据通常会被编译器直接放置在 ROM/Flash 中,而不是 RAM。
为什么这些设施很难抽象?
标准库委员会(WG21)在处理这些问题时面临三大挑战:
- 多样性: 某些 DSP 或 NPU 的寄存器模型与通用 CPU 完全不同,很难写出一套通用的 API。
- 不可移植性: L2 缓存的大小在移动端和服务器端天差地别,一旦在代码中硬编码,可移植性就毁了。
- 零成本抽象原则: 任何标准库的包装都不能比手写的汇编或裸指针操作更慢。
标准库的最新努力:std::atomic 和内存模型
这是 C++ 表达硬件困难设施最成功的例子。
内存顺序(Memory Ordering): 通过 std::memory_order_acquire/release,C++ 成功地抽象了不同 CPU 架构(如 x86 的强内存序与 ARM 的弱内存序)在缓存一致性上的差异。
C++在硬实时系统的缺陷
1.自由存储(new/delete)
- Predictability,可预测性:分配所需的时间取决于可用空闲内存的大小,内存碎片化会导致性能随时间推移而下降。这意味着对于许多系统而言,自由存储无法使用,或者只能在启动时使用(不进行释放就不会产生碎片)。
- Fragmentation 碎片化: 自由存储的大小是有限的,在分配和释放对象后可能会出现碎片化。在对象分配和释放后,可能会留下一些未使用的内存或空间。堆中这些未使用的空隙或空间被称为内存碎片化。由于这些空隙很小,这样的内存位置无法用来存储新对象,导致内存空间浪费,随着时间的推移,总的可用自由存储远小于初始可用的自由存储。
问题不在于 new 本身,而在于 new 和 delete 一起使用,这会导致一系列的内存分配和释放。详细参见(强烈建议阅读): Hard Real-Time and C++ Predictability
替代方案包括静态分配、栈分配和使用存储池。
2.避免使用dynamic_cast
尽量避免在性能敏感的代码中使用 dynamic_cast, 这是因为在标准的 C++ 实现中,当你执行 dynamic_cast<Target*>(ptr) 时,系统需要检查 ptr 指向的对象是否真的派生自 Target。编译器会生成代码去遍历“类继承树”(Inheritance Tree)。如果继承关系很深或存在多重继承,这种遍历非常耗时且运行时间不确定(不是常数时间)。在实时系统(如航天器、自动驾驶)中,这种不确定性是不可接受的。
2005年Bjarne Stroustrup的解决方案(质数和取模): Fast dynamic casting
2.禁用异常
处理异常所需的时间取决于从异常抛出点到捕获点之间的距离(以函数调用次数衡量)以及在此过程中需要销毁的对象数量。如果没有合适的工具,很难预测这个时间,而目前还没有这样的工具。C++异常机制仍基于栈展开(stack unwinding),这在现代标准(如C++23)中未根本改变。处理时间非恒定,取决于运行时状态(如栈深度、析构器调用),在硬实时中仍不可预测(无法预先保证最坏情况时间)。标准未引入确定性保证。
T4. 论文、访谈或演讲
The Log-Structured Merge-Tree
The Log-Structured Merge-Tree (LSM-Tree)
核心设计思想: 延迟与批处理 (Defer and Batch)
LSM-Tree 的核心优势在于它改变了传统 B-Tree 的写入方式。传统 B-Tree 在插入新记录时,通常需要进行随机磁盘 I/O 来定位并更新特定的叶子节点 。
- 延迟写入:LSM-Tree 不会立即将新数据写入其最终的磁盘位置,而是先将其存入内存中 。
- 批处理迁移:通过一种类似于“归并排序”的算法,将内存中的数据批量、级联地迁移到磁盘组件中。这种方式将随机写转化为顺序写,极大减少了磁盘磁臂的移动,性能提升可达一到两个数量级 。
技术实现:
- $C_0$ 组件 (Memory-resident):完全驻留在内存中 。它不需要固定的 B-Tree 结构,可以使用如 AVL 树或 2-3 树等更高效的内存数据结构 。
- $C_1, C_2, …, C_k$ 组件 (Disk-resident):驻留在磁盘上的树形结构 。每一层都比上一层更大 。
- 优化顺序访问:磁盘组件的节点会被打包在连续的多页磁盘块(multi-page blocks)中,以实现高效的磁臂利用 。
基于LSM Tree的数据库:
- 嵌入式键值存储引擎: 谷歌的LevelDB, Facebook的RocksDB
- 分布式 NoSQL 数据库: HBase
C++之父2025中国:现代 C++ 的跨世纪演进
C++的演化
之所以做这个演讲,原因在于, 我注意到很多人还在用上世纪八九十年代的方式写C++代码,这让我感到很难过,在当今我们明明可以写出更好的代码。我今天将介绍一下现代的 C++,同时也会将其视为一个整体:不仅是那些最新的特性,而是几十年来不断创造和改进的成果。
好的设计始于问题:
- 我想构建一个分布式 Unix 系统。在 1979 年,没有一个编程语言能满足我的所有需要。
- 我需要高效的硬件操作,就像 C。
- 还需要管理复杂性的抽象能力:就像 Simula,一个灵活的“强”静态类型系统。
所有好的解决方案基本上都始于一个好问题——而且是一个难题。
C++ 的诞生源于我来到 Bell 实验室,那时候觉得我必须得搞些大事,因为当时的 Bell 实验室确实是一个很棒的地方。我决定要搞一个分布式 Unix 系统。要是成功了,我们就能提前十年坐拥 Unix 集群。但当然,这种工作我一个人干不了。
首先发现的问题之一是,当时没有任何一种编程语言能够满足我构建分布式 Unix 系统的所有需求。第一,这种语言必须有处理底层事务的能力,例如设备驱动程序、进程调度器、内存管理器等等;同时,它还得必须具备高级特性,以便我们能够摆脱对硬件的依赖,从而拥有像包含进程和通信模块这样的高级特性;既然系统是分布式的,这些都必须被抽象化,你就不能依赖共享内存和指针之类的东西。总而言之,我意识到我需要这样的一个东西。
核心理念:在代码中直接表达思想。例子:
- 数学:tensor, polynomial
- 工程:Matrix, Fourier transform
- 图形学:Shading, gnome, path
- 生物学:DNA string, protein
- 电信:Buffer, channel
- 航空航天:Electric motor, route
- 汽车:vehicle, car, pedestrian
- 金融:instrument, transaction
- 计算机科学:map, task, image, file, edge - …
- 还得让其易于接受
- 唯一的限制就是你的想象力
- 注:大多数优秀的软件都是“润物细无声”的(most good software is invisible)
当时我在 Bell 实验室,处理硬件的底层语言自然是 C 语言。我之前有过面向对象编程的经验,也熟悉通过 Simula的静态类型系统来管理复杂性。我也正是这样写的。该项目的核心思想是将硬件的抽象层次提升到更适合人类理解的程度。每个领域都有一些基本概念,我们希望能直接用代码来表达它们。我不想自己当编译器,把那些高层次的概念记在脑子里、写在白板上,然后再去写底层代码。我希望高层次的想法能够直接用代码表达出来。这大致就是这里面的关键理念。
仅仅做到这一点还不够。你必须以一种潜在用户能够接受的方式来实现它。我年轻那会儿做研究员的时候,电脑配置并不高,所以我必须得在如今看来性能极其低下、运行缓慢的机器上跑程序。多年来,这对我很有帮助,因为不同电脑之间的差异很大。
优秀的设计,基于合理的原则:
- 灵活的静态类型系统 - 可扩展性(Extensibility) - 零开销(Zero overhead) - 显式类型转换尽可能少(Minimial explicit type conversion)
- 资源管理 - 防止泄露(No leaks)
- 错误处理 - 提供保证(Guarantees)
- 灵活的并发支持 - 不局限于一种风格(No one style)
当代 C++ 能比以往所有早期 C++ 更好地实现这些目标。
我们需要阐明一些原则。首先得有灵活的静态类型系统;所谓灵活,是指它可以表示各种各样的事物,而不局限于计算机科学的某个特定领域。为了降低成本,它必须具有可扩展性。我希望尽可能减少显式的类型转换、强制类型转换等等,这些操作在 C 代码中随处可见,但 Simula 中没那么多。我不希望出现内存泄漏。我希望资源管理能够有效维护现有资源。错误处理必须提供保证,并支持灵活的并发性。这就是我今天演讲的主题。
好的工具随需求而演进:
- 为什么要演进? - 世界在变化 - 面对的问题也在变化 - 我们自己亦在变化
- 优秀的工程依赖于反馈和演进 - 例如,泛型编程 (Generic programming),编译期时计算 (Compile-time programming) ,模块 (Modules)。
- “要是有人宣称自己有完美的编程语言,他要么是传销要么蠢,或者二者皆是。(Someone who claims to have a perfect programming language is either a salesman or a fool, or both.)”(—— Bjarne Stroustrup, 1980s onward)
- “就算是我也能设计一个更好看的语言。(Even I could design a prettier language.)”(—— Bjarne Stroustrup, 1980s onward)
一个问题是,为什么一门编程语言需要改变?
C++之所以会变,其中一个原因,也是它当初设计成“可以改变”的原因,显然是因为我当时没办法设计出理想的编程语言。我的团队规模有限。除此之外,我也认为不可能有一种编程语言完美适用于所有人、所有情况。所以,我们必须跟上世界的变化,跟上写代码方式的变化,并与之保持同步。
此外,优秀的工程设计依赖于反馈和改进。也就是说,我们尽最大努力构建一个系统,然后观察运行情况——观察哪些有效,哪些无效,然后进行改进;这正是所有工程领域共通的基本工作方式。在设计时,既知未来会发生某些事情,就必须将未来可能发生的事情纳入考量。你会有一个总体的方向,知道自己想要实现什么,也明白将来一定可以做得更好。所以不能把改进的道路给堵住。某些语言经过精心设计,旨在阻止你从事任何计划外的操作;而 C++ 的设计哲学恰恰相反——它被精心设计成能够适应新的挑战。
稳定性与演进
- 稳定性 (Stability):过去能用的现在依然能用 (what used to work well, still works well) - 演进 (Evolution):我们如今往往能做得更好 (usually, we can do even better today) - 现实世界的进步:开发者如何抓住那些必要的变化? 现在面临两个问题:我们想要发展,但也需要稳定性。许多组织要求代码必须能够运行数十年。我们有些代码是在 20 世纪 80 年代、90 年代写出来的,至今仍在运行。这一点至关重要。我们曾多次尝试简化语言,但从未成功。开发者和用户都不希望他们的代码出现问题,所以我们需要稳定性。我们同时还需要发展,需要从现实世界的问题中汲取灵感,并解决问题,而不是将其变成一种脱离实际的学术演练。
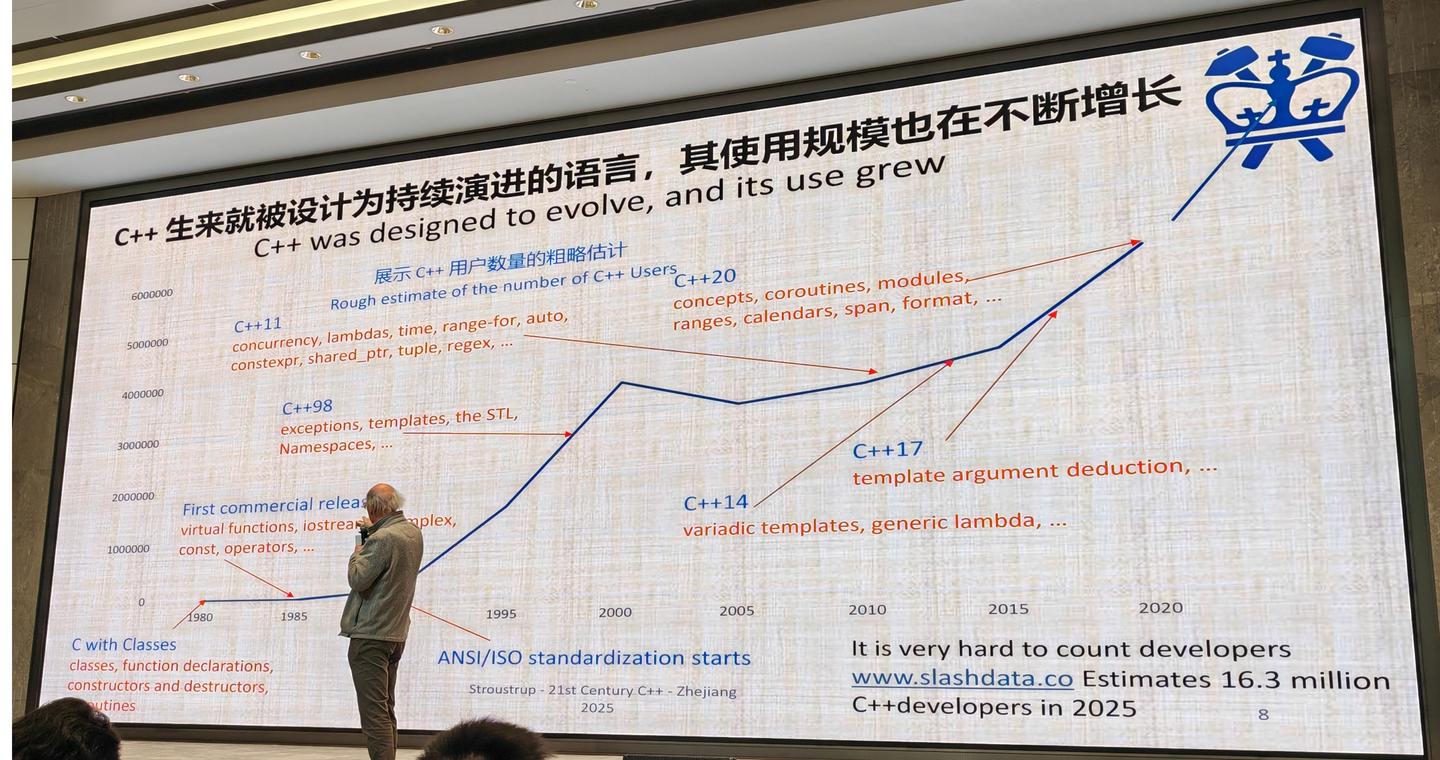
这里我们看到一张 C++ 历年发展历程的图表,展示了用户数量、以及他们最初接触 C++ 时所体验到的各种功能。需要指出,统计用户数量非常困难;这图只是我的估计,后来有人说我大错特错。实际上,有机构统计出有1630万用户,这意味着我的估计偏差了大约 2.5 倍。这个偏差算是好的。
那些新东西不是当代 C++ 的全部。如果你去看网上那些文章和 YouTube 里的视频等等,会看到人们对着最新、最炫酷的东西大谈特谈,但那并非全貌。我们拥有的语言是一个整体,各个特性相互支持、相互补充。我们既会沿用几十年来一直在使用的传统方法,也会采用新技术,它们完美契合,这一点至关重要。C++ 的真正目的在于编写优秀的代码。

让我坚持下去的动力,也是我认为的关键所在,是编程语言的价值在于它的应用范围和质量。这里我们列举了一些具体应用。比如,用于制作电影和动画的软件。还有一个服务器集群,里面运行着许多复杂的大型程序。甚至还有咖啡机也在用 C++ 编程。我喜欢咖啡,我的办公桌上就有一台咖啡机。
我不参与语言之争,因为很多语言的实现里就是大量用 C++ 的,所以还是别在这里挑起语言之争了。
我的背景是分布式系统。我觉得分布式系统的应用才是最有趣的。重要的是我们能做什么,而不是具体的细节。在这里,我重点关注:
- 资源管理 (Resource management) - 包括控制生命周期和错误处理
- 泛型编程 (Generic programming) - 包括 concepts
- 模块 (Modules) - 包括去除预处理器
- 指南及其施行 - 如何保证写出“21 世纪的 C++”?
如何编写 21 世纪的 C++代码
我说过会研究资源管理和泛型编程的问题。然后,我想到一个难题:在一个充斥着遗留代码、且程序员们接受的训练早已过时的世界里,我们该如何真正使用这些新特性?我们如何在这门语言上迈出前进的一步?我们该如何编写出真正属于 21 世纪的 C++,而不是 20 世纪的 C++?
资源管理:C++ 的基石
- 资源是你必须获取并随后释放(归还)的东西 - 显式或隐式 - 例子:内存,字符串,锁,文件句柄 (file handles),sockets,线程句柄 (thread handles),事务 (transactions),着色器 (shaders),…
- 防止资源泄露 - 避免手动释放 - 代码里不要有 free、delete,或者是类似的资源释放
- 每个资源都由一个句柄表示 - 为获取和释放负责 (Responsible for access and release) - 代码里不要有 malloc、new,或者是类似的资源获取
- 每个资源句柄都根植于一个作用域中 - 句柄可以从一个作用域移动到另一个
我们从资源管理开始。这实际上是在 C++ 开发的最初两周就开始考虑的问题,因为我之前从事操作系统和机器架构方面的工作,深知我们不能泄漏资源。如果资源泄漏了,各种糟糕的事情就会发生。比如,如果你在为太空探测器编程,无论泄漏何种资源(比如一块内存),其结果就是探测器失效,你便没法派宇航员去火星或其他地方。
资源指的是任何需要获取、随后释放的东西。释放操作需隐式进行,因为我们可能会忘记释放资源,抑或是错误地释放两次。我们不想遇到这种麻烦,而且从很久之前就理应避免这么写。但不知为何,人们仍然会写出需要显式释放的代码。不要这样做。如果你写出显式释放的代码,那么代码很可能存在问题。 不要直接写 free、delete 以及类似的操作,所有这些都必须隐式进行。
我们实现的方式是用一个句柄 (handle) 来代表资源,这个句柄控制着对资源的访问。资源通常是程序的一部分,例如操作系统、内存管理器、内存池管理器、文档管理器等等。句柄负责资源的获取和删除,并提供使用该资源所需的正确操作。
提升抽象层次

template<typename T>
class Vector { // vector of elements of type T
public:
Vector(std::initializer_list<T>); // acquire memory; initialize elements – constructor
~Vector(); // destroy elements; release memory – destructor
// ...
private:
T* elem; // pointer to elements
int s; // number of elements
};
void fct()
{
Vector<double> constants {1, 1.618, 3.14, 2.99e8};
Vector<string> designers {"Strachey", "Richards", "Ritchie"};
Vector<pair<string, jthread>> vp{ {"producer", prd}, {"consumer", cons} };
}
我举一个最简单、最传统的例子:一个vector。从最底层开始,首先需要有指针 elem和一个整数 s,用来表示元素的数量,C 风格代码就是这么写的。但是,我们希望提升到更高的抽象层次,使用必须正确初始化的类型。此外,还需要一个析构函数,在退出作用域时正确地清理资源。
于是,我们可以在这里写出 Vector
我们曾经在网上举办过一个比赛,主题是C++中最酷的特性是什么,一位叫 Roger Orr 的人回答是:
}
你看,就是在大括号这里,所有神奇的事情都发生了。先是vp的析构函数被调用,然后是 designers和constants;并且这个过程是递归的,当vp的析构函数被调用时,它会调用pair函数的析构,pair又会调用 string的析构和线程析构函数,以此类推。这样我们就简化了原本可能很复杂的部分,现在看起来非常简单。
我们每个资源句柄都是类似这样的东西,一个vector就是一个资源句柄。我们可以控制对象的生命周期,这非常重要。我们可以控制对象的构造、销毁、复制,以及将对象的句柄从一个作用域移动到另一个作用域的能力,所以我们拥有完全的控制权。这正是许多现代 C++ 的关键所在。
我们每个资源句柄都是类似这样的东西,一个向量就是一个资源句柄。
生存周期控制 (Control of lifetime)
- 对简单且高效的资源管理是必要的 - 构造 (Construction) - Before first use establish the invariant (if any) - 构造函数 Constructor - 析构 (Destruction) - After last use establish the resource (if any) - 析构函数 Destructor - 复制 (Copy) - Copy: a=b implies a==b (regular types) - 复制构造函数 copy constructor X(const X&) - 复制赋值 copy assignment X::operator=(const X&) - 移动 (Move) - 在作用域之间移动资源 - 移动构造函数 move constructor X(X&&) - 移动赋值 move assignment X::operator=(X&&)
现代C++的代码示例:提升抽象层次
我来展示一些现代 C++ 的例子。有些人认为“你必须阅读所有包含各种复杂内容的代码”,我选择这个例子就是为了颠覆这种固有观念。首先是引进标准库 (import std)。我们稍后会讲到模块 (Modules) 这个东西。随之用标准库的东西写出一个包含字符串和整数的哈希表。
我到底想做什么呢?这个来自我的朋友 Afred Aho,他是 AWK文本处理工具的设计者之一,如果你对编译器和编译相关的东西感兴趣,他应该很出名,因为他写过一本关于编译器的教科书(指龙书);他给了我 !a[$0]++这个命令行,可能不是每个人都理解:这个代码读取文件中每一行,寻找只出现过一次的行,然后将其输出。他问我“要是你该怎么做?”于是我就(用 C++)实现了一样的功能,
按行去重的代码示例 1(C风格:面向过程):
// the AWK program (!a[$0]++) relies on implicit I/O and loops
// 思路: 直接遍历,用unordered_map给字符串计数, 判断是否重复。
import std;
using namespace std;
int main() // print unique lines from input
{
unordered_map<string, int> m; // hash table
for (string line; getline(cin, line);)
if (m[line]++ == 0)
cout << line << '\n';
}
把文件中每一行放到line变量里,然后把line放到一个unordered_map里,如果是第一次见到它,则将之输出。 这是一个相当简洁明了的程序,但重要的东西不在表面。这段代码没有内存分配和释放,没有涉及size,没有错误处理,没有显式类型转换,没有指针,也没有用预处理器。所以,如果你之前觉得 C++ 只是 C 的一个变体的话,现在就应该明白并非如此。
这个程序效率很高,但我们可以做得更好。这种演示程序的写法,实际工作中几乎不会这么做。
更可能的做法是创建一个函数,用于收集所有输入信息,然后将其存储在一个vector
按行去重的代码示例 2 (C++风格:无需计数,单独函数,消除拷贝):
{kind=link}
// 思路: 定义单独的功能函数,收集收入到set,转换成vector并返回.
import std; // 需要编译器开启 C++20/23 Modules 支持
using namespace std;
vector<string> collect_lines(istream& is) // collect unique lines from input
{
unordered_set<string> s;
for(string line; getline(is, line);)
s.insert(line);
// C++23: std::from_range 标签构造函数, 告诉编译器,右边的参数是一个range
return vector<string>(from_range, s);
}
int main() {
// 编译器通常会使用 NRVO (Named Return Value Optimization) 直接在目标位置构造对象,完全消除拷贝。
// 即使编译器没有优化,也会触发 移动构造函数 (Move Constructor),仅仅交换指针的所有权,代价极低。
auto lines = collect_lines(cin);
for (const auto& s: lines) // 建议加上 const,避免不必要的修改
cout << s << '\n';
return 0;
}
你可能会认为这里存在vector的拷贝,但实际没有,这里只是将函数作用域内构造的对象移动给lines;实际上,程序会直接在外面构造lines对象 ,根本没有开销。这是是零开销的抽象 (Zero-overhead abstraction)。我在 1983 年就将这种优化构建到 C++ 中,而现代 C++ 能保证在许多情况下可以进行移动。
最后有了lines,我们将其输出。这段代码不是 C 风格的,这很重要。现在的代码已经相当高效,但仍然可以做得更好。例如,为什么不直接从 istream_view中构建unordered_set?
输出按行去重 #3 -使用 vector的移动构造函数 - 相比操作 new、指针和delete,既快又简单
- 更优解:直接在 lines中构造 vector(1983 年就有了) - 拷贝消除 (copy elision)
按行去重的代码示例 3(直接构造:面向对象):
// 输入input,直接构造set,然后拷贝构造
struct Line: string {};
istream& operator>>(istream& is, Line& ln) { return getline(is, ln); }
vector<string> collect_lines(istream& is) // collect unique lines from input
{
// 直接构造,而不是缺省的空构造,再修改。
// 思维方式的转变: 从 "手写算法控制数据流动" 变成了 "构建数据流水线 (Pipeline) 并直接实例化"。
unordered_set<string> s {from_range, istream_view<Line>{is}}; // construct the set directly from input
return vector {from_range, s};
}
auto lines = collect_lines(cin);
将输入字符串按行读取,直接放入set,然后返回vector。不错,只有一个问题:标准库没有Line类型。正如字符串string作为读取单词的抽象,我希望有Line作为一行内容的抽象,解决方案是Line就是能一整行读进来的字符串。这很容易做到,下面就是一种方案:Line就是能一整行读进来的字符串。
注:传统的面向对象编程
- 不要痴迷于只使用新特性
- 许多旧的特性仍然必不可少,并且往往是完成其擅长任务的最佳选择。
关键在于,这是经典的面向对象编程。我们的新代码以 Simula 的形式进行面向对象编程。我把它放在这里是为了说明传统方法仍然非常有价值,就像现在一样。
有人说 C++ 是一种面向对象的编程语言。它确实是一种对面向对象编程支持很好的语言,但这并非全部。我这里也展示到了很多泛型编程,如set、map和vector。但它仍是面向对象的,就像输入和 I/O 操作一样。当然,还可以进一步优化。虽然还有一些字符串复制操作,但我时间有限,就不赘述了。
调优:“洋葱原则”
“对某些代码来说,调优是必要的,”Stroustrup 转入了性能优化的话题。“但我们都听过 ‘避免过早优化’ 这个建议。重要的是要在优化前后都进行性能测量,同时在设计接口时就要考虑优化空间。”
调优 (Tuning)
- 对某些代码必不可少
- “避免过早优化 (do not optimize prematurely)”
- 永远在优化前后进行测量 (Always measure before and after optimization)
- 若有需要,设计接口以允许优化 (Design interfaces to allow optimization if needed)
- well defined
- type rich
- with enough information to enable checking and optimization
- 复杂度管理 (Complexity management)
- Make simple things simple!
- 抽象层次 (Layers of abstraction)
- 剥开得越多,流的泪就越多(The more layers you peel off, the more you cry)
我会指出依然可以做些什么。如果我们想做得更高效,可以“剥掉”一层抽象。我们有一些定义良好的接口,允许我们以任何喜欢的方式实现。要是还想要更高的性能,可以再下降一个层次,在更低的抽象层次编写代码。要是还不够就再下降一层。还不够的化,可以一直深入到硬件。我们甚至可以为那些对性能要求很高的抽象层提供专门的硬件。这实际上是许多最重要的 C++ 应用的关键。人们会编写很底层的代码,这些代码被良好的接口隐藏起来,例如他们会用这种方式使用 FPGA 或 GPU,但代码看起来仍然像普通代码,我们可以理解并操作。这非常有用。
我称此为“洋葱原理 (onion principle)”。原因很简单,就像剥洋葱一样,你会忍不住流泪。剥开得越多,流的泪就越多。同样, 在实现抽象层次较低的事物时,也就是一层层剥去抽象层,你需要编写更多的代码,犯错的机会也就更多。你犯的错越多,流的泪也就越多。这就是“洋葱原理”,一种处理抽象问题的方法。
资源与错误 (Resources and errors)
- 总而言之 - 不要泄露资源 (Don’t leak a resource) - 不要让资源处于无效状态 (Don’t leave a resource in an invalid resource)
- 当一个错误发生时 - 在退出函数之前: - 把访问过的每个对象都置于有效状态 (Put every object accessed into a valid state) - 释放该函数拥有的每个对象 (Release every object that the function owns) - 如果每个资源都有句柄,这很容易做到;如果没有,那就基本上不可能了。
错误处理
我们还需要处理错误。在实际的程序中,在现实规模下,我们必须处理错误。而且我们不应该留下资源,也不能让对象处于错误状态。要是犯了错误,需要退出当前程序,我们必须确保“离开后所有仍然存活的对象都处于良好状态”。否则,之后我们会还遇到错误,情况会变得更糟。在退出函数之前,请将每个对象访问都置于有效状态,释放该函数拥有的所有对象,然后将问题留给其他程序处理。
void f(int n, int x)
{
Gadget g{n}; // a Gadget may hold resources, e.g., memory, locks and file handles
Gadget* pg = new Gadget{n}; // explicit new: don't!
// ...
if (x<100) throw std::runtime_error("Weird!"); // leak *pg; g not leaked.
if (x<200) return; // leak *pg; g not leaked.
// ...
}
这里有一个正确操作以及错误操作的例子。这里的 Gadget g 是一个局部变量,它需要一些资源 —— 这里无需具体说明它需要哪些资源,它是可析构的,能把这些资源清理掉。这里还有一种方法 —— 遗憾的是它并不少见,人们直接用 new创建对象,并赋值给指针;我看到很多人写这样的代码,因为他们在 Java、C# 等语言里就是这么干的。但是,在后面的代码里,我们必须记住手动销毁 pg ,而 g 则会被自动销毁,不用管 g拥有什么资源,如果有的话;它可能拥有很多资源,可能有一个文件句柄,可能占用了大量内存,而所有这些都会在这里被清理掉。如果我们抛出异常,它也会被清理掉;如果只是使用 return语句,它也会照样被清理掉。然而,所有这些情况下,我们都必须记住 delete pg。经验表明,我们经常忘记这件事情,导致错误的发生,然后不得不处理它,然后仍然会犯错。
所以, 经验法则是:不要直接使用 new (no naked new)。new 应该放在资源句柄中。所有类型的资源都应该如此。如果你不想用标准的内存管理器,你也可以定制一个,不过这些都是资源句柄。不要让它们出现在你的应用程序代码里。 要是你在应用程序代码中使用了new操作,我便怀疑你的代码中有 bug:因为你必须记住 new的释放。要是我看到delete操作,我照样会怀疑是否存在 bug:你是否在所有地方都执行了删除操作?你是否重复删除了某些内容?这更糟糕!我们不希望发生这种情况。
有哪些方式来报告错误呢?基本上有两种。一种是返回一个需要被检测到的返回码 (return code),用来判断是否存在错误、或是任务是否完成;另一种是抛出异常 (exceptions)。如果你预测到错误的发生,或者你认为这种情况比较常见,那就返回一个错误码,使之得到立即处理。这是用于文件句柄这类任务的。
然而,有很多错误无法在本地处理,这时候就用异常。举个例子,用远程文件系统,请求通过网络传输;网络错误虽然罕见且难以处理,但也不是每次获取资源时都会遇到的,人们往往会忘记进行相关测试。有时,程序是在文件系统出现之前编写的,网络是中间环节, 所以程序并不知道这些错误的存在,因此需要异常来处理这种情况。我们会用异常处理构造函数、运算符以及几乎所有无法准确预测的情况。这种方法实际上非常高效。目前的实现中,有些速度很慢,而一些效率更高的异常处理正在开发中,用于小型嵌入式系统。
void fct(jthread& prod, string name)
{
ifstream in {name};
if (!in) { /* ... */ } // possible failure expected
// ...
vector<double> constants { 1, 1.618, 3.14, 2.99e8 }; // memory exhaustion possible
vector<string> designers {"Strachey", "Richards", "Ritchie"}; // nested construction
// ...
jthread cons { receiver };
pair<string, jthread&> pipeline[] = {.{"producer", prod}, {"consumer", cons}.}; // 加上. 因为md编译无法通过
// ...
}
来看一个例子。这里,我有一个示例函数,它接收一些参数,然后打开一个文件。显然,我可以预料到这个文件可能没有被打开——也许是拼错了文件名,也许是传入的文件名本身就有问题,此时无法进行读写操作。另一方面,内存耗尽的情况虽然罕见,但也并非不可能。比如这里,我把三位语言设计者的名字加上首字母添加到了代码中。你会把错误处理语句和 if 语句放在这里吗?首先,这种错误很少发生。其次,代码会变得非常丑。 如果你要写这样的代码,并且需要测试所有可能出现的错误,代码就会变得一团乱麻,要写的代码量至少会增加三到四倍,因而也会产生更多的错误。这应该是异常处理的用武之地。而 ifstream这里是异常处理不适用的地方,因为应该在本地处理掉:你明确知道错误可能发生。
顺便一提,这里提到了异常处理的新实现,它们速度很快,非常适合小型系统。这是 CppCon 204大会 - Khalil Estell 演讲的一个精彩视频;如果你使用 Clang 或 GCC 的话,可以下载这个实现,用它代替默认实现。
总结一下,要管理资源,不要泄露。为此,我们需要能够将对象句柄从一个作用域转移到另一个作用域。我们需要控制对象的创建、销毁和复制。我们需要能够系统地处理错误。
泛型编程
话题步入到泛型编程。今天在 C++ 中使用的泛型编程源于 Alex Stepanov 的工作,他利用各种机制实现了零开销。这让我们能够编写出更简短、更易读的代码,同时,它也是整个 C++ 标准库的基石。无论是容器、并发原语、内存管理、I/O、字符串处理,还是正则表达式等等,都广泛运用了我即将介绍的泛型编程技术。
void sort(Sortable_range auto& r);
vector <string> vs;
// ... fill vs ...
sort(vs);
array<int, 128> ai;
// ... fill ai ...
sort(ai);
list<int> lsti;
// ... fill lsti ...
sort(lsti); // error: a list doesn't offer a random access
那么,我们究竟想用它做什么呢?举个例子,我希望能够对任何“满足可排序条件的元素序列”(或者说范围)进行排序。为此,我们首先需要定义什么是 Sortable_range。但在现阶段,可以先简单地理解为:一个 Sortable_range需要满足一系列“约束(constraints)”,规定了排序操作所必需的条件。现在可以取一个字符串向量,填充一些合适的内容,然后对其进行排序,编译器会处理剩下的部分;我们可以对一个包含 128 个整数的array做同样的排序;我们可以尝试对一个list
现代泛型编程带来的一个关键区别是,如今你可以精确地定义 Sortable_ranges这个 concept。这意味着,对类型条件的检查可以恰好发生在函数调用的地方,从而提供更清晰的错误信息。
同样重要的是,我们希望尽可能多地让编译器掌握信息,这样就不必在代码中重复写出来。如果我们不得不手动明确指定所有细节,不仅繁琐,也增加了犯错的机会。因此,在上面的例子中,容器的类型是编译器已知的,无需再额外说明;容器中元素的类型也是已知的;甚至元素的数量也是已知的。默认情况下,排序使用“小于”(<)操作进行比较,而random_access_range这个 concept 会确保该操作确实存在。这套机制让我们非常接近泛型编程的理想目标。
我当初设计对泛型编程的支持、亦即后来的模板 (templates) 时,初衷是要满足三个条件:首先,它必须能够完成超出我想象的功能;其次,我希望它是零成本抽象,否则人们就会转而去编写底层代码;最后,我希望有像刚才展示过那样的良好接口。但我发现这三个条件无法同时满足。我走遍世界各地与专家交流,他们也无法同时做到这三个条件。我们实际上花了 20 年时间才找到解决这个问题的方法。但在此期间,我们已经实现了前两个条件:通用性和零开销。
template<typename Random_access_iterator, typename Compare = std::less>
void sort (Random_access_iterator fist, Random_access_iterator last, Compare = Compare{})
{ ... }
vector<string> v = {"CPL", "BCPL", "C", "C++"};
sort(begin(v), end(v)); // sort the vector
sort(begin(v), begin(v)+size(v)/2); // sort the first half of the vector
sort(begin(v), end(v), greater<string>()); // sort strings in accenting order
int a[] = {3, 1, 4, 2, 6, 9, 0, -1};
sort(begin(a), end(a)); // sort the array
sort(begin(a), end(a), [](int x, int y){ return abs(x)<abs(y); }); // sort absolute value
这个例子是传统的 C++98 模板。我接收一个first和一个last,它们必须是相同类型,称为 Random_access_iterator,然后还有一个比较函数。我们可以实现展示出来的所有这些有趣的事情,唯一的问题是我们实际上没有说明要求什么。这里只是用了一个“名为 Random_access_iterator 的类型”,而它没有指明 Random_access_iterator 是什么,也没有说明它必须是一个“能随机访问的迭代器”。所以这违反了语言的基本设计规则。
尽管如此,这套机制在实践中被证明极其有用,它构成了标准库的基石,支撑了无数高级应用,无论是简单还是复杂的场景都能胜任,并且保持了出色的运行效率。
我特别不喜欢“排序vector的开头,逗号,vector的结尾”这种写法;我想说“排序vector”。尽管它非常、非常成功,规模非常大,在数十亿行代码,数百万个程序中都用到,但我们需要做得更好。
概念
Concepts for specifying constraints
- A concept is a compile-time predicate – A function run at compile time yielding a Boolean – Ofeen built from other concepts
- Specify the requirements for
sort()
First try:
template<typename R>
concept Sortable_range =
random_access_range<R> // has begin()/end(), ++, [], +, ...
&& sortable<iterator_t<R>>; // can compare and swap elements
void sort(Sortable_range auto& r);
这里是对 Sortable_range的规范定义。这正是我期望排序函数所接受的参数应当满足的约束。这基本上是一个编译期函数。它的语法看起来或许有些特别,但含义非常明确:它说,如果类型 R 是 random_access_range 并且其迭代器是可排序 (sortable)的,那么 R 就是 Sortable_range。直截了当。我们没有使用函数通常的圆括号,而是使用尖括号来表示参数,但这确实是一个接收类型 R 的编译期函数。
定义了之后,我便能够说自己希望sort接收一个那样的Sortable_range。顺便说下,random_access_range和 sortable在标准中已有定义,所以你不必自己定义;就像其他函数一样,我们通常不会编写所有函数,基础的东西都在库里。你上次编写平方根函数是什么时候?对我来说是 40 多年前,因为它在库里,自从我学生时代学会如何写后,就再没写过。这里的 concept 也是如此——concept 就是编译期函数,可以接收类型参数。
概念 Concepts
- 刚才那个简单的 Sortable_range对于基础库而言还不够通用。 - 我们还需要明确一个比较准则。
- concept 可以接受多个参数 - 它们不仅仅是“类型的类型”
- 标准库里的算法和 concept 非常通用, - 通常带有许多参数和重载
template<typename R, typename Compare = ranges::less>
concept Sortable_range =
random_access_range<R> // has begin()/end(), ++, [], +, ...
&& sortable<iterator_t<R>, Compare>; // compare elements using Compare
template<Sortable_range R, typename Compare = ranges::less>
void sort(R& r, Compare cmp = {})
自此,我就可以定义标准库中常见的排序函数了。它稍微复杂一些:接受一个 Sortable_range,以及一个比较函数 Compare,该比较函数可以用来对通过迭代器访问的内容进行排序。所以,如果 R 是一个Sortable_range,那么它就是一个“可排序的范围”。同时它是一个 random_access_range,你可以使用比较函数 Compare进行排序。注意,这实际上是一个非常普通的函数,它接受两个参数。而且通常情况下,你确实需要用到两个参数。这不是类型定义之类的东西,它是一个函数。我们可以写出通用的代码。
vector v = {1, 5, 2, 8, -1};
sort(v); // sort using <
sort(v, ranges::greater{}); // sort using >
list lst = {1, 5, 2, 8, -1};
sort(lst); // error: a list isn't a Sortable_range - no random access
好了,现在可以写出这样的代码了。如果我有一个 vector,我可以对其进行排序,也可以反向排序。但如果我对一个list执行相同的操作,会立即失败。此时,程序会给出一个还算合理的错误信息,不会延后到模板实例化等。写过 C++ 的人都知道,以前的错误信息简直糟糕透顶,因为编译器根本不知道我们想做什么,无法给出相应的错误信息;直到模板实例化时,它才能够将信息整合起来。所以我们这才可以做得更好。
使用 - 但是接受一对迭代器的传统 sort()怎么办?
- 基于概念的重载
template<typename Iter, typename Compare = ranges::less>
concept Sortable_iterator =
random_access_iterator<Iter> // has begin()/end(), ++, [], +, ...
&& sortable<Iter, Compare>; // compare elements using Compare
template<Sortable_iterator Iter, typename Compare = ranges:less>
void sort(Iter first, Iter last, Compare cmp = {});
vector v = {1, 5, 2, 8, -1};
sort(v.begin(), v.end()); // traditional
sort(v); // more directly expressed
当然,我之前说过稳定性很重要。在设计好功能之后,当然也要确保旧的排序方式仍然有效,而它们确实如此。这里定义了一个 Sortable_iterator,它是一个 random_access_iterator ,并且能进行排序(sortable)。我可以定义接受两个迭代器的sort函数,并且明确地指定它必须接受迭代器 Iter作为参数,而不仅仅是简单地把它们的名字写作 Iterator。现在我既可以用旧的方式对vector进行排序,也可以用新的方式排序。这两种排序方式的选择取决于函数重载,非常简单。
概念 Concepts
- 我们一直都有“concepts ”这一思想。例如: - C built-in types: arithmetic and floating (from 1972 or so) - STL concepts: iterators, sequences, and containers (since the early 1990s) - Mathematical concepts: monad, group, ring, and field (from a couple of centuries) - Graph concepts: edge, vertex, graph and DAG (since 1736)
- 除非程序员脑海中对涉及的“concepts ”有清晰的认知,否则任何泛型程序都无法工作 - What is relatively new is that we can define them to be used in code.
- C++ concepts 是可以接受类型实参的编译期函数(谓词) - Simple - General
实际上,我们一直都有“concept”,只是以前无法表达出来;比如在 C 语言中,内置类型既有算数类型(Arithmetic types),也有浮点类型。Dennis Ritchie 早在 70 年代就说过这一点。STL 也一直支持迭代序列和容器,自从 Alex Stepanov 定义出来就一直如此。现在我们称之为 sequences 或 ranges,但这只是技术层面的差异。数学中也有很多“concept”,例如代数里的那些,以及图操作、图中的概念:如图的顶点,我们已经用了几百年了。唯一的新变化是,我们现在可以用代码来表达它们,编译器也能理解它们。没有它们,你就只能依赖文档标准,而编译器不会读文档,大多数程序也不会。concepts 就是编译期函数,总体上是个很简单的东西。我们有必要学习如何使用它。我注意到,人们需要一段时间才能适应“现在可以对类型参数编写函数”这一事实。
概念通常由其它概念构建而成 (Concepts are often built out of other concepts)
template<typename R, typename Pred = ranges::less>
concept Forward_sortable_range =
ranges::forward_range<R> // has begin(), end(), ++, ...
&& sortable<ranges::iterator_t<R>,Pred>; // compare elements using Pred
构建 concept 时,我们通常会基于其它 concept 进行构建。这里的例子是Forward_sortable_range,它由 forward_range 和可用 Pred的排序的对象构成。forward_range和sortable都是标准库中有的。
- requires运算符是一种底层机制,用于检查构造是否为有效的C++。
- 它对于表达底层要求至关重要,但在高层级代码中最好避免使用,在那些地方使用已有名称的概念(它们往往由 requires构建而来)更易于理解和维护。
template<typename T, typename U = T>
concept equality_comparable = requires(T a, U b) { // use patterns
{a == b}-> Boolean;
{a != b}-> Boolean;
{b == a}-> Boolean;
{b != a}-> Boolean;
}
有时,我们必须深入底层,使用语言的基本特性。如上是 equality_comparable 的定义。有两种类型:T 和 U,我们可以比较 T 和 U 类型的对象,前提是代码里这些操作合法且返回布尔值。这些操作被称为使用模式 (use patterns),它们简单易懂地告诉你能对该类型的变量做什么,从而指定要求。这说起来容易做起来难,但确实很有效,人们已经用了有一段时间了。
使用模式 (use patterns)
- 在模板中,concept 明确了能够对其参数进行的操作 (Concepts specify what a template must be able to do with its arguments) - 而不是说模板参数“必须是什么”(Not exactly what an argument type must be.)
- 例如,在 requires (X a, Y b) { a+b; }中,a+b 可以由下面各种方式实现 - X operator+(X, Y); // if a is an X and b is a Y - X X::operator+(const Y&); // if a is an X and b is of a class derived from Y - Y operator+(const X&, const Y&); // if an X can be implicitly constructed from a Y and a Y can be implicitly constructed from a X - Y operator+(Y, X&); // if a Y can be implicitly constructed from a X and b is an X - … 还有很多 …
- 这很重要 - Handles mixed-code arithmetic - Handles implicit conversions - Interface stability (as the definition of + changes)
这么写的原因是,我们想明确说明“允许做的行为”。从泛型编程的角度来看,我们希望了解“如何处理这些值”,而非具体实现方式。运算符的实现方式多种多样。例如,这里展示了如何用不同的方法实现 X 和 Y 的加法运算。实现方式有很多种,在程序的生命周期内,加法运算的实现方式可能会发生变化,通常是为其更加通用,能够处理更广泛的数据类型。这使得写泛型代码变得非常容易,因为我们不必总是关注运算的具体实现。这还意味着处理混合的运算,例如之前的 T 和 U,或者这里的 X 和 Y,它们不必是同一类型。此外,它还支持隐式转换。这意味着,如果有人更改了加法运算的实现,我们无需修改程序代码,只需重新编译即可。这保证了接口的稳定性。
概念的益处 Benefits of concepts
- 支持好的设计 - 就像类 (class) 那样
- 可读性,可维护性 - 过度使用无约束的类型 (auto和typename是问题的来源)
- 大幅改进错误信息
- 重载 - 像函数一样,但更简单
concept 有巨大的影响。我们在编程语言中获得适当类型并产生 concept。它支持好的设计,就像类 (class) 做的那样;它提供了可靠性、可维护性;你可能首先注意到的是它大幅改进了错误信息,并且按我们期望的方式处理重载。
模块
模块 (Modules)
- 顺序依赖 (Order dependence):
#include "a.h"
#include "b.h"
可能调换顺序后又不一样的行为
#include "b.h"
#include "a.h"
- #include纯粹是文本包含
- 这表明
- #includeis transitive
- much repeated compilation
- subtle bugs
- 模块化 (Modularity)
import a
import b
调换顺序后行为完全一样
import b
import a
- import 不是传递的
- 这表明编译工作只需执行一次
现在讨论另一个现代化设施:模块 (Modules)。模块有很多好处,其中之一是我们现在可以像处理其他代码一样处理模板,只需将其放入模块即可。
我们真正想要的是“模块化 (Modularity)”。C 语言“假装”有了模块化,C++ 现在也在假装,但#include并不是真正的模块化。#include A后跟#include B可能产生与#include A不同的结果,因为这些包含文件中的内容可能实际依赖于另一个。编译器必须一遍又一遍地查看以检查依赖关系。#include是文本包含,而问题是包含是可“传递”的。所以当我包含 A 时,A 可能包含 D、E、F,而 F 可能包含更多,依此类推。你会得到大量可能根本不知道的声明。当我包含 A 时,我原本只想使用 A ,但实际上我获得了 A 包含 D、E、F的一切内容。这会带来大量需要编译的东西。
借助模块,我们终于能够在 C++ 中实现真正的模块化。如果 import A 和 B,我可以按任意顺序进行,不会影响结果。此外,import不是可传递的;你只获得从模块显式 export的内容,而不会看到模块实现所需的细节。
模块 (Modules)
- 提升代码质量:实现真正的模块化(特别是避免宏的污染) - 更快的编译速度(不是一星半点,是好几倍) - 与模板、类和函数采用相同的源码组织结构
export module map_printer; // we are defining a module
import iostream;
import containers; // Imports are not transitive
using namespace std;
export // this template is the only entity exported
template<Sequence S>
void print_map(const S& m) {
for (const auto& [key, val] : m) // access key and value
cout << key << "->" << val << '\n';
}
这里有一个简单的例子。我写了个 map_printer模块,它理应包含实现这个 map_printer所需的很多东西,不过为了简洁,这个 map_printer设计得很简单。本质上它是一个模板,使用了各种组件,其中一些细节你并不需要关心。而最终,从这个模块唯一导出的,只有一个函数。
模块本质上包含两部分:一是表示模块代码结构的图(graph),二是一张导出声明的哈希表。这看起来很直观:你声明一组要导出的接口,而编译器则会预先处理好这些接口背后的代码表示。你无需回到源代码去反复解析字符和 token,这些工作早已完成了。
我们曾经为此思考了很长时间。实际上,就连最初设计#include机制的人也明白,模块是更优越的方案。只是受限于当时的环境和技术,我们没法实现它。如今,在已有数十亿行 C++ 代码的生态中,要正确无误地引入模块并处理好所有细节是非常困难的,例如,我们要允许模块与传统的#include共存,并逐步迁移。我们做到了,但耗费了漫长的努力。
标准库模块化 (Module std)
- 模块 std包含了完整的 std命名空间
引用: open-std.org
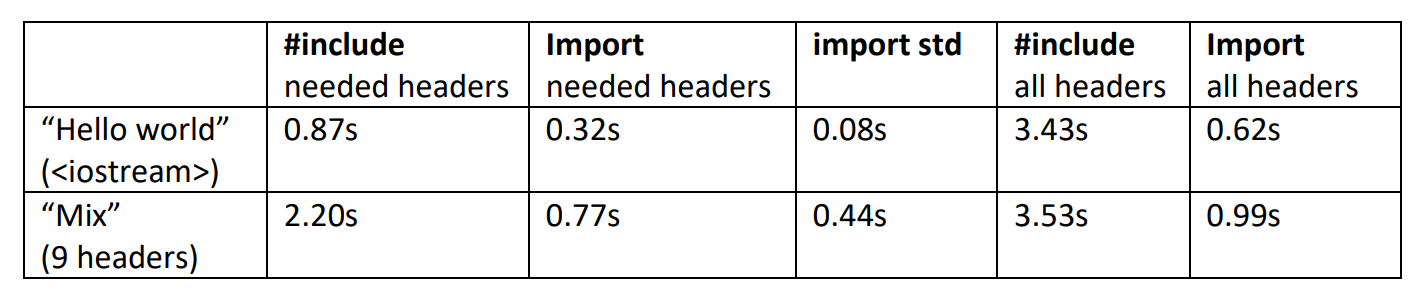
每当有新技术出现时,总会有人质疑其开销。人们总倾向于认为新东西太昂贵或太慢。为了回应这一点,我进行了一个小实验。我想要一个名为 std的模块,期包含整个std命名空间——基本上就是整个C++标准库。随之我测试了两个版本的“Hello, World!”程序:一个使用传统的 #include
更重要的是,在实际项目中,如果你在多个.cpp文件中重复#include同一个头文件,编译器需要反复解析和处理其内容;而模块的预编译特性意味着,这些重复性工作被极大地消除了。在这个实验中,我可以说获得了百倍的编译速度提升。能对一项已有 50 年历史的技术实现百倍改进,是非常罕见的。通常来说,即便是 10% 的提升都已属不易。
这个实验也直接促成了std标准模块的诞生。它现在已经是语言标准的一部分,我自己就经常用它。
模块 —— 不仅仅用于标准库
- 25 倍性能提升 - 不过不要期望所有情况都像这样 - Daniela Engert: 视频Contemporary C++ in Action - CppCon 2022(已整理)

这是来自德国嵌入式系统开发的例子。Daniela Engert 三年前做了这个实验——话说回来模块实际上不是新东西,我们几年前就能跑了。实验是这样的:在传统方式下,我们需要 #include 该嵌入式系统的设备支持头文件;这个头文件经过预处理后会展开成非常庞大的代码量,达 50 万行之巨。就算你没见类似情况,这也可能比你想象的更为常见。编译器表现其实不差,处理这 50 万行展开后的代码大约需要 1.5 秒,速度已经很快了。然而,当改用模块import 相同的功能时,编译时间降至约 0.062 秒。这是在早期较旧的编译器和模块实现上得到的结果,即便如此,她依然获得了超过 25 倍的加速。当然,我们并不能指望每次使用模块都能带来 25 倍乃至 100 倍的提升。根据我的经验,一个合理的期望值是编译时间能加快大约 7 到 10 倍。即便如此,这也意味着对于一个原本需要一小时构建的大型项目,现在可能只需要 5 到 10 分钟。这是一个质的区别——我个人的咖啡消耗量都减少了,因为不再需要长时间等编译完成。我强烈推荐大家试一下。
另外,我想推荐 Daniela Engert 在 CppCon2022 (整理在本博客)的演讲,你可以在YouTube上找到。她展示了如何运用模块以及其它现代 C++ 特性来构建真实的系统,内容既深入又全面,既有例子也有原理阐述。我建议各位去看看,它能让你对我今天所讲内容的高级形态有一个更具体的认识。准备好,这可能会震撼到你。
新特性重要吗?
- 经过基本测试后,我已经很多年没见过资源泄漏了
- 我曾经重新设计了一个 1990 年代的东西,以提升可靠性 - 那可不是个玩具,那玩意已经投入生产 20 多年了 - 关键要领:简化! - 新设计不小心提升了 100 倍速度!
- 我没有使用超出本次演讲内容的更高级的东西 - 在生产代码中 - 实验中受到的限制较少
- 这些技术使用非常广泛 - 资源管理 - 错误处理 - 泛型编程
我所展示的这些设施,如今在主流编译器上均已实现,完全可以投入使用。而且,我已经很多年没有看到资源泄漏或内存损坏的问题了,这些现象几近消失。有一次我希望取代 一个 1990 年代的设计,以获得更高的可靠性、更少的错误。其核心无非是遵循像资源管理这样的基本原则,并无他物。仅仅是这些原则,而意外的是,它还带来了 100 倍的性能提升。之所以说意外,因为这原本并非需求之一。只是在我简化代码之后,它让编译器和优化器更容易生成高效的代码。我对实现团队展示的效果感到非常惊讶,完全没意料到。你真该看看他们向我展示性能数据时我的反应,我下巴都惊掉了。
所有这些我展示过的技术——资源管理、错误处理和泛型编程——在今天的C++中都是立即可用的。它们已经被应用于各种领域:从金融行业的大型低延迟交易系统,到数据中心服务器农场,再到真实的农业自动化系统,以及汽车控制系统等等,我都亲眼见过实际应用。
并发
并发 Concurrency
- 为了效率 - 因而有很多不同风格 - 许多优化技巧
- 广泛的支持 - 线程和锁 - 共享 - 并行算法 - Cooperative cancellation - Futures - 协程 (Coroutines) - …
- 这是一个重要话题,需要一个专门的讲座来详细讨论
我本想花些时间谈谈并发 (Concurrency),因为现代软件系统中并发无处不在。但时间实在有限,要完整阐述可能需要一个小时甚至一天。不过我可以简要说明以下,现代 C++ 已经提供了丰富的并发支持:线程和锁、并行算法(parallel algorithms)、协作取消(cooperative cancellation)。C++26 中还有更多常见的并发功能,它提供了一套更通用、更高效的抽象。虽然 C++26 是明年的标准,但它已经在 Facebook 和 NVIDIA 等公司的生产环境中投入使用。所以,你们很多人用的程序中很可能已经用到了它。
不要被困在 20 世纪
- 现代编程方式的优势适用于大多数场景
- 升级代码很难 - 但可以极其有益 - 可以循序渐进完成
- 新代码无需延续过时的范式
- 怎么做? - Avoiding sub-optimal techniques is difficult - Old code - Old habits
例子:不要对指针使用下标
- 而是使用包含足够信息的抽象层进行范围检查。 - 需要运行时支持。
- “Make simple things simple.” - simpler than “old style” - shorter - At least fast
代码示例: 指针衰退(Pointer Decay)和手动管理内存长度,这极易导致缓冲区溢出(Buffer Overflow)。
/* Common Style */
void f(int* p, int n);
int a[100];
// ...
f(a, 100); // OK? depends on the meaning of n
f(a, 1000); // likely disaster
这里有个非常经典的操作数据的方式。你有一个指针p和一个说明元素数量的整数n。现在我可以传递一个指向数组的指针a以及数组的元素数量。只要函数f真的知道n是元素数量,一切安好;但在第二列那里,我手滑了一下,写成了 f(a, 1000)。就算f里有范围的越界检查,它也无法捕获所有错误:因为根本没有 1000 个元素,只有 100 个。
核心方案:使用 C++20 std::span std::span 是一个轻量级的、不拥有所有权的视图对象。它内部只包含两个东西:指针 + 长度。它能自动从数组、std::vector 或 std::array 中推导长度,从而消除了手动传递大小的错误。
/* Better*/
void f(span<int> s);
int a[100];
f(span<int>{a}); // verbose
f(a);
f({a, 1000}); // checkable
为解决这类问题,C++ 提供了名为span的设施:一个span对象本质上封装了一个指针和元素数量。现在,我可以将函数f的参数声明为接受一个span。在调用时,只需将数组a转换为span传递进去即可。它能正确工作,因为span会携带信息,表明它指向一个包含 100 个整数的数组。非常好。
与大多数基于模板的泛型编程一样,编译器已经知晓数组a的元素类型是int,且其大小为 100。因此,使用span不仅能让你写出更简洁的代码,也大幅提升了安全性。虽然理论上仍可能通过特殊语法人为制造错误,但我们当然不必那样做;更重要的是,此类易错代码在代码审查或静态分析工具面前会变得非常显眼。在实践中,我们大多会采用更简洁、更安全的span写法。
此外,span本身定义了一个范围(range),这意味着我们可以直接对其调用sort等算法,或使用基于范围的 for 循环 (range-based for loop)。我们将抽象级别从容易出错的底层提升到了一个新的层次。
span 的概念并不新鲜。我曾与 Dennis Ritchie 讨论过它。Dennis Ritchie 曾试图将其纳入 C 标准,但他的建议没被采纳。顺便说一下,他称此为“胖指针 (fat pointer)”,而我称之为 span。这源于我一直在制定的一套指导原则,现在这套原则已被纳入标准。关于这点,我们暂且先谈到这里。
指南与其施行 (Guidelines and enforcement)
- 我们无法改变语言 - 但可以改变它的使用方式 - 稳定性/兼容性是主要特性 - 逐步采纳新功能和技术至关重要
- 指南 - 个别规则可遵守可不遵守 (Individual rules can be used or not) - 不完全强制 (Enforcement is incomplete) - Available now: The C++ Core Guidelines
- Profiles - 强制施行的连贯指南规则集 (Enforced coherent sets of guidelines rules) - Being worked on in WG21 and elsewhere - not yet available - 解决技术债务 (Addresses technical debt) - Address safety and simplicity concerns - Help focus education
关键在于,我们无法完全摒弃旧的编程方式。毕竟,全球有数十亿行现存代码和数百万程序员,他们不可能接受自己的代码被破坏。大约每两周,我就会收到这样的请求:“C++ 太复杂了,你得简化下它。”是的,C++ 确实复杂——这既是其作为一门历史悠久语言的特征,也是其作为通用语言所不可避免的。然而还有人说:“干嘛要简化?务必加上这两个新特性,我真的很需要它们。”你看,他们既希望语言更简单,又要求加入更多功能。这本身就很困难,尽管通过巧妙的泛化设计没准能部分实现。“哦还有,无论如何,千万别破坏我现有的代码。我可有一百万行,你动不得。”
你看, 人们的请求包含三个相互矛盾的目标(简化语言、增加特性、向后兼容)。我们无法同时满足三者。我的结论是:你不可能通过直接改变语言本身——我们已经尝试过多次,结果都行不通。真正的出路在于改变我们使用语言的方式,而这需要清晰的使用指南 (Guideline)。
目前已经有了一些指南,例如“使用span,而非f(指针, 计数)”这样的规则。我们拥有许多更优秀的抽象:vector、string、线程、智能指针等等。我们可以倡导大家使用这些更现代的特性,因为它们更好、更快、更安全、写起来也更简单。但现实是,人们往往并不遵循这些指南。原因很多:他们太忙而无暇学习,要学的东西太多,或者他们的编译器还没更新。
因此,我们需要的是指南的“强制执行机制”,这也就是所谓的“Profiles”。目前,我们已有一些可用的指南。我个人正在研究并推荐的是《C++ 核心指南 (C++ Core Guidelines)》,你可以在 GitHub 上找到。
C++ 核心指南
C++ 核心指南 (C++ Core Guidelines)
这份指南是 C++ 现代实践的核心基础,我见过它的中文译本。其中部分规则已经能够在微软的静态分析工具、Clang-Tidy 以及 JetBrains 的 C++ 分析器中得到检查与执行。虽然这算是一种支持,但我更希望将其规范化,即通过“Profiles”的形式将其纳入语言标准,从而能够系统地强制执行一套连贯的代码规则。
超集的子集 (Subset of superset)
- To make progress - Do something new and stop doing something old.
- Simple subsetting doesn’t work - We need the low level/tricky/close-to-the-hardware/error-prone/expert-only features - To implement higher-level facilities efficiently - Many low-level features can be used well
- Extend language with a few abstracions - Use the standard library - Add a tiny library (the GSL) - No new language features - Messy/dangerous/low-level features can be used to implement the GSL - Then subset
- We want “C++ on steroids” - Simple , safe, flexible, and fast - Not a neutered subset
这背后的思路是一种“先取超集,再取子集”的哲学。我们不能简单地对语言进行子集化处理,因为如果直接移除那些最危险、最底层的语言设施,我们将无法实现所需的高级抽象,也无法编写特定的底层程序。这也解释了:为什么许多高级语言在需要时,会通过unsafe 块或直接调用 C/C++ 等其它语言来实现关键部分。
我们采取的方法是,首先用一组精心设计的高级抽象来扩展语言,往往体现为各种库。有 STL 中的vector、sort等等各种东西;也有 GSL (Guidelines Support Library)—— C++ Core Guidelines 提供的指南支持库。当这些抽象足够完善并广泛可用后,开发者便不再需要频繁地直接使用那些原始的底层特性。此时,我们便可以在特定的、要求安全性的场景中对语言进行子集化,有选择地禁用那些危险且容易出错的角落。这就是我们的想法:“先取超集,再取子集”。
核心规则 Core rules
- 有些人不适用全部规则 - 至少一开始如此 - 常用逐步采纳的方法 (Gradual adoption is very common)
- 有些人需要额外规则 - 为特定需求
- 我们一开始聚焦于那些核心规则 - 我们希望最终每个人都能从中受益。
- 核心中的核心 - 无未初始化的变量 (No uninitialized variables) - 无范围越界或者违规使用 nullptr (No range or nullptr violations) - 无泄露 (No leaks) - 无悬垂指针 (No dangling pointers) - 无指针造成的的类型违规 (No type violation through pointers) - 无失效 (No invalidation)
我希望在标准中看到的是:有“Profiles”能够消除未初始化的变量、消除范围越界和违规使用空指针、消除资源泄漏、消除悬垂指针 (Dangling pointers)、消除指针造成的类型违规 (type violation),等等问题。我现在不深入讨论,因为时间不够,但我们能做到。所有这些都已经过实验验证。在 C++ Core Guidelines 中已经部分实现,但尚未纳入标准。这是我在未来工作中要做的,但这并非科幻。
建议纳入标准的初始 profiles 集合 The initial set of profiles suggested for the standard
- 算法 (Algorithms) - all ranges, no dereferences of end()
- 算术 (Arithmetic) - catch overflow and underflow, catch implicit narrowing conversions
- 类型转换 (Casting) - ban them, 全部禁用
- 并发 (Concurrency) - eliminate deadlocks and data races (hard)
- 初始化 (Initialization) - every object initialized
- 失效 (Invalidation) - no access through invalidated pointer (incl. dangling pointers)
- 指针 (Pointers) - no subscripting of built-in pointers (use span, vector, string, etc.)
- 范围 (Ranges) 范围 - range errors caught
- RAll - every resource owned by a handle
- 类型 (Type) initialization, range casting, invalidation, pointers
- 联合体 (Union) - no unions (use variant, etc.) 禁止使用 union(应使用 variant 等);
每一项都没有进入 C++26一个巨大的错误 ☹ 实现工作正在进行中
我们想要的是广泛的保证:算法、算术、类型转换、并发、指针和范围验证,所有这些都可以提供。并且,应该仅在人们请求时才强制执行。这就是 profiles 的理念。例如,我希望所有资源都由资源句柄处理。或者我希望保证每个对象都被初始化。我正在为此努力,并已提议它进标准。不幸的是,它没进入 C++26,我认为这是一个悲剧和重大失误。但我已经概述了如何解决这些问题,以及我期望未来能够解决之。
C++模型
C++模型 The C++ model
- 静态类型系统 Static type system
- 值语义和引用语义 Value and reference semantics
- 对内置类型和用户定义类型提供同等支持 Equal support for built-in types and user-defined types
- 灵活且高效的泛型编程 Flexible and efficient generic programming
- 编译期编程 Compile-time programming
- 系统且通用的资源管理 Systematic and general resource management (RAll)
- 高效的面向对象编程 Efficient object-oriented programming
- 直接使用机器和操作系统资源 Direct use of machine and operating system resources
- 通过库支持并发 Concurrency support through libraries (supported by intrinsics)
- 最终消除c预处理器 Eventually eliminate the C preprocessor
我总结一下当代C++的模型。我们有一个静态类型系统,对内置类型和用户定义类型给予同等支持。我们有值语义和引用语义。基本上,我们希望值类型在初始化、销毁、拷贝等方面行为正确,但使用指针、引用等来实现它们。我们希望系统化和通用的资源管理。我们支持面向对象编程,也支持泛型编程。虽然我没深入细节,但你可以实际上在编译时做很多很多事情,我们也支持代码的编译期执行,声明函数使其如此,这种函数非常接近纯函数 (pure function),因其无法使用编译时不可用的东西。一如既往,我们希望能够直接使用机器和操作系统资源——因为这是 C++,我们仍然可以做真正高效的事情,利用硬件中的特定设施。并发支持通过库来实现,我们可以支持多种并发模型;我的经验是,并非每个人都希望并发只有一个样,现代系统中有如此多的并发。我们可以摆脱 C 预处理器,它是复杂性和 bug 的来源。而且,你在今天的例子里没有看到任何宏,这是因为我几乎不再使用,除非必须使用开源代码。
简要介绍 C++23-26 的部分新特性
- C++23 - cppreference.com
-
- 、 - - 、 - - C++26 - cppreference.com
-
- 、 - - -
C++23 已经可用一段时间了,虽然还没有 100% 在所有地方实现,但已接近。有一系列设施:生成器 (Generator) 让协程 (coroutines) 更有用。print让你不必显式使用«,并且直接处理 Unicode 字符。如果你要为了效率进行无锁编程,可以去 cppreference 看下 hazard pointers 和 RCU。此外还有线性代数和 SIMD 支持。这些都是好东西,明年就会得到了。投票正在进行中。
静态反射的泛型编程 GP with Static Reflection (C++26)
- 一个简单的例子:为类成员生成包含名字、偏移和大小的描述符 (descriptor)
- 若能做到这点,我们可以在得到一大堆运行时支持 - 生成 I/O 操作 - 从不同格式序列化/反序列化 - 其它语言调用 C++,或者反过来
静态反射
struct data_member_descriptor
{
string_view name;
size_t offset;
size_t size;
};
template<typename S>
consteval auto get_layout()
{
constexpr auto members = meta::nonstatic_data_members_of(^^S);
array<data_member_descriptor, members.size()> layout;
for(int i = 0; i < members.size(); ++i)
{
layout[i] = {
meta::identifier_of(members[i]), // member name
meta::offset_of(members[i]),
meta::size_of(members[i])
};
}
return layout; // returns an array<data_member_descriptor, members.size()>
}
这里展示一个从明年标准中能得到的例子:静态反射 (Static Reflection)。 静态反射本质上是一种能够让程序在编译时向编译器查询类型信息的机制。你们已经看到,泛型编程在很大程度上依赖于编译器所知晓的类型信息。而静态反射提供了一个更基础层面的设施,使你能够获取编译器所掌握的、关于类型的全部结构化信息。
假设我想获取一个结构体或类的成员描述符 data_member_descriptor。对于该类的每一个非静态数据成员,我都希望获得一个包含其名称、在内存布局中的偏移量以及大小的描述符。这是我曾在构建多个系统时迫切需要的功能,而通常你不得不通过添加标记或要求用户以特定方式提供这些信息,整个过程往往非常繁琐。
需指出的是,我在此展示的语法和功能尚未成为正式标准,预计将在下一版(即 C++26)中引入。但是,你此刻就可以在 Compiler Explorer(也常被称为“Godbolt”)上找到三个在线可用的实验性的实现,它们几乎能够完成未来标准所规划的全部功能,包括我将要展示的一切。所以,这并非科幻,而是近在眼前的未来。
核心的语法非常有趣:关键在于那个“双帽操作符” ^^。将^^置于一个类型名之前时,它便能够从编译器那里提取出关于该类型的反射信息。我是在说:编译器,请给我类型S的所有非静态数据成员的列表。如果S是一个结构体或类,这便能生效。随后,我就能利用这些信息来写一些非常普通的代码:例如,生成一个包含所有成员描述符的数组。由于这些成员信息直接来自编译器,编译器知道其确切数量,因此我也就知道了数组的大小,并能轻松地遍历它。对每个成员,我向编译器查询其标识符名称、偏移量和大小;随后,我便能构建并返回完整的布局信息。这再次体现了移动语义如何使得高效、低成本地传递这类信息变得简单——不同的语言特性正在相互支撑,协同工作。
这种新颖而强大的能力被封装在一个普通的函数内部,其使用方式与任何其他函数别无二致。这简直是送给库开发者的礼物。它虽然用途广泛、不受限制,但其主要目的是为了支撑更强大的库的开发。
静态反射的实例代码 Use of static reflection
- 反射的结果就是普通的 C++ 数据(如数组),并非黑盒
struct X {
char a;
int b;
string c;
};
constexpr auto Xd = get_layout<X>();
- 现在 Xd 就是一个 data_member_descriptor,其值为 { {“a”, 0, 1}, {“b”, 4, 4}, {“c”, 8, 24} }
- 这里的字符串字面量就是 string_view 中的内容。
我们可以尝试调用以下这个函数。为演示简洁起见,我使用了一个简单的结构体,它包含一个 char 、一个int和一个 string 成员。当我请求获取其布局时,便会得到类似这样的输出:{ {“a”, 0, 1}, {“b”, 4, 4}, {“c”, 8, 24} }。
这可以用于各种各样的用途,包括生成接口、与其他语言相互调用等等。你可以访问 cppreference.com 网站查阅相关信息,搜索“反射”(Reflection),会找到很多相关信息和例子。
所以 C++ 的设计初衷就是为了不断发展,而且它至今仍在不断发展。它正在为解决实际问题提供支持。比如这个例子就是一个实际存在的问题。我亲眼见过人们在很多大型项目中都需要这样的结构体信息。
作为结束,我们最后回到这里:编程语言的价值在于其应用范围和质量。我们正在努力接近这个目标。我们正尽力地接近理想状态。
要达到完美还需要很多时间、很多年,而完美只是暂时的。
Interview: Bjarne Stroustrup on 21st century C++, AI risks
Interview: Bjarne Stroustrup on 21st century C++, AI risks, and why the language is hard to replace C++之父 Bjarne Stroustrup 接受 DevClass 采访,讨论了如何编写现代 C++、试图取代该语言的问题、AI 风险,以及为什么拥有多个编译器(实现略有不同)实际上是件好事。

如何强制以现代风格编写 C++?Stroustrup 告诉我们这是一个问题。“你实际上无法在大段代码中遵循指南。我们需要支持。我正在研究由我称为配置文件(profiles)的东西来强制执行的指南,它们表明,我希望这一系列保证得到满足,然后就会被强制执行。”
他说,试图从语言本身中移除“危险、复杂的东西”是没有未来的,即使“人们一直要求更简单的 C++版本。”他告诉我们,问题在于“像指针、数组和类型转换这样的危险、复杂的东西,是我们实现良好抽象所必需的……你可以做的是,你可以在抽象的实现之外移除它们。例如, operator new 和 operator delete 就不应该出现在应用代码中。”
他是否担心 AI 对 C++编程的影响? “是的,我确实有严重的担忧。我不是说它不会带来帮助,但它确实有引导人们走向过去大家一直做的事情的倾向。这不是一个好的发展方向。此外,我担心人们会失去发现问题的能力,因为他们已经习惯了有人为他们完成这些工作,”他说。
另一个趋势是新语言的涌现,其中一些基于 C++,例如谷歌的 Carbon 项目。这些语言有未来吗?“如果你专注于某个小领域,设计出比 C++更好的东西很容易,但 C++的一个优势是它能在非常多样化的领域工作,”斯特劳 strup 说。另一个问题是“如果这些语言中任何一种成功,它们必须能够与 C++、Python 等交互。如果我们不注意,我们不会得到像 C++这样过于庞大的单一语言,而是会得到 10 种都不足够且每一种都拼命试图与其他语言互操作的语言。”
“知道你速度适中的方式之一是,一半的人抱怨你太慢,另一半人抱怨你太快,”斯特劳斯特鲁普说。“是的,我希望能比标准委员会快一点。标准委员会非常庞大,里面的人关心很多事情,这会拖慢进度……但可能更多 C++开发者觉得它进展太快了,”他告诉我们。
C++之父2024中国: 重新认识 C++
12 月 5 日,美国国家工程院、ACM、IEEE 院士、C++ 之父 Bjarne Stroustrup 在「2024 全球 C++ 及系统软件技术大会」上发表了题为《重新认识 C++:跨世纪的现代演进》的演讲。屏幕上,演示文稿的第一页就令人印象深刻:“C++ 几乎可以实现我们所期望的一切!(C++ can be almost all we want to be)”
从构建操作系统到开发高性能游戏引擎,从支持人工智能框架到驱动航天器控制系统,C++ 一直是系统级软件开发的首选语言。然而,这位编程语言大师并不是在炫耀 C++ 的强大,而是要指出一个关键问题:“正因为它如此强大,我们更要谨慎选择正确的使用方式。就像 goto 语句——它无所不能,所以我们几乎从来不用它。同样的,虽然用 20 世纪 80 年代的方式写 C++ 也能完成任务,但这显然不是最佳选择。我们需要明确自己的真正需求,避免重蹈覆辙。”
Stroustrup 指出了一个常见的认知误区: 人们往往把“熟悉”等同于“简单”。对很多开发者来说,见过千百遍的代码写法看起来简单,而新的特性和方法则显得复杂。
“我们必须努力避免这种思维定式,否则就会永远停留在 20 世纪。”他强调道,“今天,我想谈谈我所认为的当代 C++、现代 C++ 的基础是什么。我认为,当代的编程方式能让代码变得更简单、更安全、更高效,远胜于任何旧版本的 C++。
谈到 C++ 的发展历程,Stroustrup 指出:“一些关键特性和技术已有多年历史,比如带构造函数和析构函数的类、异常处理机制、模板、std::vector……等等。另一些则是较新的发展,如 constexpr 函数和 consteval 函数、lambda 表达式、模块、概念、std::shared_ptr……等等。关键在于将这些特性作为一个整体来运用。”
“不要盲目使用所有新特性,也不要局限于仅使用新特性,”他强调道,“如果想了解最新特性和未来发展方向的更多细节,可以参考相关的技术讨论视频。我更关注的是如何将语言作为一个整体来开发好的软件。因为最终编程语言的价值体现在其应用程序的质量之中。”
“这就是 C++ 的基石:构造函数(constructor)和析构函数(destructor),”Stroustrup 说道,“如果需要获取任何资源,那是构造函数的工作;如果需要归还资源,那是析构函数的工作。这里我们将抽象层次从机器级的指针和大小提升到了更高的层次。我们把它包装成一个类型,这个类型行为正确,有赋值操作,有访问函数,并且能正确清理。”
他特别指出了资源管理机制的递归性:“string 拥有一些字符,这里的 pair 拥有一个 string 和一个 jthread。jthread 拥有对操作系统线程的引用。这些都是递归进行的。神奇之处在于最后的闭合花括号——那里是所有东西都被隐式而可靠地清理的地方。”
为了做好资源管理,Stroustrup 强调了对生存期的控制:
- 构造:首次使用前建立对象的不变量(如果有的话);
- 析构:最后使用后释放所有资源(如果有的话);
- 拷贝:a = b 意味着 a == b,且它们是独立的对象;
- 移动:在作用域间转移资源所有权;
“这些机制让我们能够开发出更安全、更可靠的代码,”他总结道,“因为资源管理不再依赖于程序员的记忆力,而是由语言机制自动保证。”
协程:状态保持!
“说到协程(coroutine),这其实是个有趣的故事,”Stroustrup 回忆道,“在 C++ 发展的最初十年,协程是我们的一个重要优势。但后来一些公司因为它不适合他们的机器架构而反对,结果我们失去了这个特性。现在,我们终于把它找回来了。”
协程的特点是能在多次调用之间保持其状态。Stroustrup 用一个生成斐波那契数列的例子来说明:
generator<int> fibonacci() // 生成 0,1,1,2,3,5,8,13 ...
{
int a = 0; // 初始值
int b = 1;
while (true) {
int next = a + b;
co_yield a; // 返回当前斐波那契数
a = b; // 更新状态
b = next;
}
}
for (auto v: fibonacci())
cout << v << '\n';
“这里的妙处在于状态的保持,”他解释道,“我们有计算的状态——a、b 和 next——它就这样不断地计算下一个斐波那契数。协程已经被嵌入到迭代器系统中,所以我们可以用简单的 for 循环来获取数列中的值。”
但这个例子还有一个小问题:“这是个无限序列,显然会带来问题,我们会遇到溢出。那么如何限制它只生成特定数量的值呢?”Stroustrup 展示了改进的版本:
template<int N>
generator<int> fibonacci() // 生成前 N 个斐波那契数
{
int a = 0;
int b = 1;
int count = 0;
while (count < N) {
int next = a + b;
co_yield a;
a = b;
b = next;
count++;
}
}
for (auto v: fibonacci<10>()) // 只生成十个数:0,1,1,2,3,5,8,13,21,34
cout << v << '\n';
“虽然标准库对协程的支持还不如我想要的那么完善,”Stroustrup 说,“但这个例子中使用的 generator 已经在 C++23 中可用了。如果你使用的是较早的编译器,还可以使用 Facebook 的 coro 库或其他任务库。这个例子很好地展示了模板和协程是如何和谐地协同工作的。”
“协程为我们提供了一种漂亮的方式来处理需要保持状态的计算,”他总结道。“它让代码更容易理解,也更容易维护。这正是我们一直追求的目标:简单的事情简单做。”
CppCon2024演讲: C++异常与嵌入式
C++ Exceptions for Smaller Firmware 视频链接, 演讲者是 Khalil Estell(前 Google 工程师,曾参与 Pixel Watch/Buds 开发)。
这也是该系列“三部曲”中的第一部。视频的核心论点完全挑战了嵌入式开发的传统智慧:在嵌入式固件中,使用 C++ 异常(Exceptions)实际上可以比使用错误码(如 std::expected 或返回 bool)生成更小的二进制文件。
1. 背景与动机:为什么嵌入式开发者“痛恨”异常?
资源受限:演讲者首先介绍了嵌入式环境的严苛限制(Flash 往往小于 1MB,RAM 小于 100KB),没有操作系统,没有 printf,甚至没有堆内存(Heap)。
传统观念:通常认为 C++ 异常会导致:
- 二进制膨胀 (Bloat):引入巨大的表和库代码。
- 依赖动态内存 (Malloc):异常对象通常需要 malloc,这在禁止动态分配的嵌入式系统中是禁忌。
- 性能不确定性:抛出异常时的开销未知。
- RTTI 开销:需要运行时类型信息。
现状:因此,大家通常使用 -fno-exceptions,并依赖返回值(如 std::expected、错误码、bool)来处理错误。
2. 问题:错误码方案(Distributed Error Handling)的弊端
Khalil 在他的教学框架(SJSU-Dev2)中强制学生使用 std::expected 两年半后,发现:
- 代码“病毒式”传播:几乎所有函数都变成了 expected 类型,因为底层 I/O 错误(如 I2C 失败)需要层层上报。
- 代码膨胀:这就是视频的核心数学模型。
- 错误码模式:每次调用函数,都需要插入 if 检查和分支指令(Branch)。成本随调用次数 (Call Sites) 线性增长。
- 异常模式:成本主要在于异常表(Metadata)和 unwinder(解栈器)。成本随函数定义数量 (Function Count) 增长,而不是调用次数。
结论:在一个复杂的系统中,调用次数远多于函数定义数量。因此, 当代码规模超过某个临界点(他在图中展示大约是 550 次检查),异常机制反而更省空间。
3. 实战优化:如何让异常在 ARM 上变小?
演讲者并没有直接使用默认的异常配置,而是展示了如何通过“黑客”手段移除 bloat:
障碍 1:默认禁用。ARM 工具链默认禁用异常,或者一旦启用就引入整个标准库。
障碍 2:二进制巨大 (150KB -> 13KB) [16:52] 默认开启异常后,Hello World 从 2.6KB 暴涨到 150KB。 关键优化 [18:22]:通过覆盖弱符号 (Weak Symbols) 替换掉 GCC 默认的 verbose_terminate_handler。默认的处理程序包含了解析异常名称并打印到 stderr 的复杂逻辑(引入了 malloc, snprintf, 字符串处理等)。 Khalil 自己写了一个只有几行代码的 terminate 处理程序(死循环),瞬间将大小降至 13KB(减少了 91%)。
障碍 3:依赖 Malloc [19:37], 异常抛出时需要分配内存保存异常对象。 关键优化:覆盖 __cxa_allocate_exception。他将其重定向到一个静态缓冲区(Static Buffer)或自定义的简单分配器,从而彻底移除了对 malloc 的依赖。
障碍 4:RTTI [20:27] 实际上,编译器非常聪明。即使开启 -fno-rtti,编译器也会只为那些被抛出 (throw) 的类型保留必要的 RTTI,其余类型的 RTTI 会被剥离。因此 RTTI 的开销并没有想象中大。
4. 技术深挖:ARM 异常机制是如何工作的?
(Under the hood) [30:20] 这一部分非常硬核,详细解释了 Itanium C++ ABI 在 ARM 上的实现。
两个核心数据段:
- .ARM.exidx (Index Table):一个有序数组,存储函数地址和指向详细数据的指针。通过二分查找(Binary Search)定位当前 PC 指针属于哪个函数。
- .ARM.extab (Exception Table):存储具体的解栈指令(Unwind Instructions)和捕获逻辑。
解栈指令 (Unwind Instructions):
- 不是机器码,而是一种紧凑的字节码(Bytecode),告诉 CPU 如何恢复寄存器(如 R4-R11, LR, SP)以回到上一层函数。
- 大多数函数的解栈逻辑只需要 3 个字节 就能描述清楚。
LSDA (Language Specific Data Area):
- 包含 Call Site Table:定义了代码中的 try 块范围。
- 包含 Action Table:定义了 catch 块的类型匹配逻辑。
- 包含 Type Table:存储被抛出的类型信息。
实际上就是 Switch-Case: Khalil 指出,底层的 catch 逻辑在汇编层面就是一个 Switch-Case 语句,根据 Type Info 决定跳转到哪个处理块。
5. 数据对比与结论
模型对比:
- 错误码:每个检查点消耗约 4-8 字节(指令)。
- 异常:每个函数增加约 47 字节的元数据(如果有 try/catch),或 8 字节(如果只是传递异常)。
- 交叉点:当你的程序有大约 550 个错误检查点时,异常机制开始比错误码机制更省空间。
案例:学生的一个 MP3 播放器项目,从错误码重构为使用异常后,二进制大小反而减小了(从 56KB 降至 40KB+)。
哲学总结:Khalil 认为 C++ 异常本质上是一种 “代码压缩 (Code Compression)” 技术。它将分散在各处的错误处理指令提取出来,放入了集中的元数据表中。
6. 未来工具:Exception Insights Tool [01:14:00]
他正在开发一个工具,可以通过分析二进制文件(而非源码),结合 call graph,模拟抛出异常,来告诉你:
- 哪些异常没有被捕获(Uncaught exceptions)。
- 哪些异常路径可能导致 terminate。
- 帮助满足航空航天等领域对“所有分支都必须覆盖”的合规要求。
总结
视频传达的核心思想是:不要因为“常识”就盲目禁用异常。 只要你愿意稍微从底层去配置(替换默认的 terminate handler 和 allocator),C++ 异常在嵌入式系统中不仅完全可用,而且在代码量达到一定规模后,它是比 if (err) 更节省空间的方案。
CppCon2022演讲:现代 C++ 实战
Contemporary C++ in Action
1. 核心挑战与目标 (The Mission)
- 动机:回应社区对 C++ 标准委员会“脱离现实”的质疑,进行一次“现实核查 (Reality Check)”。
- 任务架构:
- Server:扫描目录 $\to$ 解码视频 $\to$ 网络推流。
- Client:网络接收 $\to$ GUI 渲染播放。
- 技术限制:必须使用成熟的第三方 C 库,但代码风格必须是纯粹的现代 C++(Value Types, Coroutines, Modules, Ranges)。
2. 封装遗留 C 库:万能包装器 (The Wrapper)
面对基于堆内存和裸指针的 C 库(如 libav, SDL),Daniela 拒绝了传统的 Wrapper 写法,采用了更激进的策略:
- Concepts & Requires Expressions:利用 C++20 概念约束模板。
- 值语义 (Value Semantics):
- 将 C 语言的指针(如
AVCodecContext*)封装为值类型。 - 对象像
int一样可拷贝、移动。 - 利用 RAII 自动管理生命周期,彻底消除了手动的
malloc/free。
- 将 C 语言的指针(如
3. 视频处理流水线:Generators 与 Ranges
通过 C++23 的生成器和管道重构了传统的死循环逻辑:
- 无限范围 (Infinite Ranges):创建一个永远不结束的目录迭代器 (
end()永远返回false)。 - 过滤器管道 (Pipeline):
DirectoryIterator | Filter(只看 .gif/.tiff) | Transform(打开文件) | Transform(创建解码器) - 协程生成器 (
std::generator):- 编写
make_frames协程函数。 - 控制流反转:在解码循环深处直接
co_yield frame。 - 外部调用者只需遍历生成器即可获取帧,状态机由编译器自动生成。
- 编写
4. 网络层:ASIO + Coroutines (无锁编程)
利用 ASIO 网络库,但完全摒弃了传统的回调地狱和互斥锁:
- No Mutex (零互斥锁):整个程序虽为多线程,但未显式使用任何
std::mutex。利用协程调度保证数据安全。 - 协程化 IO:
- 使用
co_await socket.async_read(...)将异步操作扁平化。
- 使用
- 结构化并发 (Structured Concurrency):
- 利用 ASIO executors 和
stop_source/stop_token(C++20jthread概念)。 - 自动取消:每个连接(Agent)独立。一旦连接断开,
stop_token触发,所有关联的 Timer 和 Socket 操作自动取消。
- 利用 ASIO executors 和
5. 错误处理:std::expected
放弃异常(Exceptions)和错误码(Error Codes),拥抱 C++23 风格:
std::expected<T, E>:函数返回一个“要么是值,要么是错误”的对象。- 管道传递:通过管道操作符处理
expected对象。 - “Disappointment Channel”:如果中间步骤出错,错误会自动流向管道末端(失败通道),只有成功的值才会进入下一步处理。
6. 模块系统 (C++20 Modules)
这是演讲中最“硬核”的炫技部分,实现了全链路模块化:
- 全面模块化:不仅自己的代码用了 Modules,还将 Boost、Libav (FFmpeg)、SDL 全部封装为模块。
- 宏隔离:利用模块机制屏蔽了 C 库中的宏定义,防止污染全局命名空间。
- 性能飞跃:
- 传统
#include <iostream>等头文件:预处理后代码量巨大,编译慢。 import std;:编译速度相比传统方式提升了 100 倍以上。
- 传统
7. 总结与成果
- 现场演示:Server 和 Client 成功编译运行(编译速度极快),并流畅播放动画。
- 代码特征:
- Simple (简单):逻辑线性化,无回调地狱。
- Concise (简洁):无样板代码 (Boilerplate),协程替代了手动状态机。
- Safe (安全):类型安全,内存安全,无数据竞争。
- Composable (可组合):Modules 和 Ranges 让代码像积木一样搭建。
Bjarne Stroustrup的一些观点
安全性
对C++安全性批评的驳斥,表态他将增加新的安全工具应对批评,为全球数十亿行C++代码带来新的解决方案。
- 第一,安全性指的不仅仅是内存安全。
- 第二,语言之间的互操作性需求往往会被忽视。
- 第三,语言切换的成本通常会被低估。
通常提到的安全性只是内存安全——这是不够的……与其他语言(包括C++和C)进行互操作的需求往往不会被提及。而且转换的成本可能非常高。这一点很少被提及。从我所看到的观点来看,我们将用大约7种不同的语言来取代C++。也许在距今四十年后,我们可能会有20种不同的语言,它们必须相互操作。这将会很困难。
许多所谓的‘安全’语言将所有底层的东西都外包给了C或C++。暂时脱离原始语言来访问硬件资源,甚至操作系统(通常是用C编写的)——甚至可能是极为古老的、藏在外部库中的“可信代码”。
Stroustrup把我们目前的情况称为“一种渐进式和进化式的方法,而不是一味追求全新的方法。”就像盖尔定律:“ 一个有效的复杂系统势必是从一个有效的简单系统发展而来的。”
归根结底,就像Stroustrup所指出的,切换语言可能看起来是在构建一个新系统,但是想越过所有旧系统的问题来解决一切,只是一个幻想。切换语言所要付出的代价可能远比你理想中的要高。
Bjarne Stroustrup: “谢谢大家。C++不是为了追求潮流而设计的,而是为了解决实际问题。四十年来,它的核心原则从未改变:零开销抽象。我们既要提供高效的硬件操作能力,又要通过强类型系统管理复杂性。”
(针对“C++是否过时”的提问)“有些人认为C++太复杂,或者认为AI会取代程序员。我不同意。 关于复杂性: 软件生态过于注重‘便利性’和‘速度’,导致核心原则被削弱。C++的复杂性源于现实世界的复杂性,我们不能为了简单而牺牲性能。 关于AI: 即使利用AI编写代码,解决问题仍然是人类的工作。AI只是工具,它可能会助长‘无意识编码’,重复过去的错误模式(如原始指针)。真正的挑战不是语言本身,而是开发者的思维方式。 优秀的开发者应该定义问题并构建模型,而不仅仅是写代码。”
未来的 C++(C++26 及以后)
“我们正在为C++26及更远的未来做规划,核心目标是:
- 并发与并行: 这是提升性能的关键。我们将引入更高效的线程管理、无锁编程工具和任务调度器,让并行计算更简单。
- 安全性: 我们正在引入‘准则检查配置文件’(Profiles),在编译期自动检测内存泄漏和越界访问。C++必须在保持高性能的同时,获得内存安全。
- 新特性: 我们正在研究静态反射(Static Reflection)和模式匹配(Pattern Matching)。这能让代码更简洁、更具表达力,且没有运行时开销。
- AI与底层: C++将在AI的底层计算(如张量操作、GPU协同)中扮演核心角色。”
问答环节精华(Q&A)
Q1(来自现场师生):C++ 如何应对 Rust 等新语言的挑战? “A: 我们不害怕竞争。C++的优势在于生态和兼容性。我们有数十亿行高质量的遗留代码,这些是无法推倒重写的。我们的任务不是重写过去,而是如何在现有基础上逐步优化。就像翻新房子,不用推倒,而是逐间升级。”
Q2:对于 C++ 开发者,有什么建议? “A: 不要只做‘搬运工’。你需要理解你写的每一行代码背后的硬件原理(Cache、内存)。 深耕领域知识: 无论是在金融、游戏还是嵌入式领域,领域知识(Domain Knowledge) 比单纯的语法知识更重要。 拥抱现代 C++: 请忘掉 20 年前的 C++ 风格。使用 RAII、智能指针、概念(Concepts)和模块(Modules)。如果你还在用裸指针和宏,那你其实是在写 C 语言,而不是现代 C++。”
Q3:如何看待数学在编程中的作用? “A: 程序员在数学上付出的努力,永远也不会白费。在C++20中引入的‘概念(Concepts)’,就是数学逻辑在类型系统中的应用。它让模板编程有了接口约束,这不仅提升了错误提示的友好度,也提升了性能。”
“C++ 的价值体现在应用程序的质量之中。在这个 AI 重构一切的时代,C++ 依然是构建可靠基础设施的基石。它不仅是一门语言,更是一种用高效代码构建美好世界的技术追求。 对于每一位开发者,我的建议是:不要害怕底层,不要停止思考。 只有理解了问题的本质,你才能写出伟大的代码。”
制定安全使用的规则
Stroustrup简要说明了一点:“小心”是行不通的。因此,虽然核心指导方针可能建议安全的编码实践,但“我们需要强制执行的规则”。
export My_module[[provide(memory_safety)]];
import std [[enable(memory_safety)]];
import Mod [suppress(type_safety)]];
文章或PDF归档
C++
- Stroustrup与Bill的对话–已归档
- Stroustrup与Pramod的对话
- Foundations of C++–已归档
- Abstraction and the C++ machine model
- C++ Primer Plus
编程技术:、
The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software By Herb Sutter
CSCI E-192 课程提供了很好的参考,他们列出的Paper主要在这里:master list.
我觉得其中每一篇的都值得一读,所以就不一一列举了。实在不喜欢的可以略读,但是也该能把握它的思想。 CPP:
Golang
其他
关于编译器
Reddit上有关于讨论编译器书单的一个话题,Recommendations for books on compilers。其中sanxiyn评论到: GCC wiki recommends a list of compiler books.
打开之后,我只选了一本: Appel. Modern Compiler implementation in ML
关于编译器书籍的评论,我想 Vladimir N. Makarov的话语为我指明了学习和阅读的方向:
If you don’t want to be compiler savvy but want to understand the compiler, I’d recommend Appel’s, Cooper’s, Morgan’s book in the same priority.
我现在还不清楚自己想不想精通编译器,所以先读这些基础的书,如果兴趣越多就读更多。
读计算机科学的经典-打好基础
过去一直有一个声音,让我们去读经典,读《红楼梦》, 读巴尔扎克,读莎士比亚,读《荷马史诗》,读《论语》… 为什么要读经典?
因为真正的美,从古至今都没有改变,改变的只是它表达美的形式和表现方式。就如,即便几千年过去了,我们仍然会觉得万里长城很美,秦兵马俑很美, 比萨斜塔很美,蒙娜丽莎很美,梵高的向日葵很美…美的事物,人们很容易得到共识。
我把这样的想法也放在了编程领域,我们该去读计算机科学的经典。读计算机科学在早先创建的时候,那些先驱者的思想,以及后来不断出现的经典。
为什么要做这件事情?因为一方面计算机的技术越来越纷繁和学科细化;另一方面,越来越多的人痴迷于科学技术产生的工具,甚至有些人痴迷于一种编程语言。正如Bjarne Stroustrup在访谈中提到:
”Nobody should call themselves a professional if they only knew one language.(没有人应该把自己视为一个专家,如果他们只知道一门编程语言)“
由此,新一代的人们开始忽略了计算机科学的本质,忘掉了那些简单而朴素的真理。只有去读经典,才能从这越来复杂和庞大的学科中,把握它最美、最精华的思想。
我打算花两年的时间,把这些经典的论文和书籍看一遍,我要回到那个简单朴素的思想起点。
一些书单
来自Reddit,更多的讨论在链接这里: Is there a list of the canonical introductory textbooks covering the major branches of computer science?
我只关心我对其中感兴趣的书,人的一生时间有限,我不可以什么书都去读。不管它写的再好,如果我对其不感兴趣也是徒劳。
- SICP (Structure and Interpretation of Computer Programs (Abelson & Sussman))
- Formal Language: A Practical Introduction by Webber
- Abstract and Concrete Categories: The Joy of Cats by Adamek et al
- Fundamentals of Computer Graphics by Shirley and Marschner
- Distributed Systems: Concepts and Design by Dollimore et al
- **Introduction to Functional Programming using Haskell **by Bird and Wadler
- ML for the Working Programmer by Paulson
- How to Design Programs(Felleisen等人)
- **Concepts, Techniques, and Models of Computer Programming **(Van Roy & Haridi
C5. 最喜欢的语言:面向现代的C++
C++的魅力:核心是零开销抽象(Zero-overhead Abstraction),不牺牲性能的前提下提升表达力;同时坚持兼容性、实用性、直接映射硬件、支持多种编程范式,让 C++ 能适配从嵌入式到超算的全场景。
1.学习建议:(BS的视频采访):
- Bjarne Stroustrup谈到,“C++是一门庞大的语言,许多人迷失在它的细节中(Don’t get obsessed with the details.)。然而,写好C++你只需要掌握一些基本技巧,其余的确只是细节”[BS12]。他的这番话也为我的C++学习指明了方向: 专注于C++核心的编程技术,忽略各种繁杂的细节。不是说细节完全不重要,而是细节可以在编程时通过Google学会,不需要浪费大量的时间去掌握细枝末节。把时间用在重要的事情上,提高学习的效率。
- Don’t try to understand everything. You can’t know everything. BS:采访
- 全局视角,不能因为树而失去森林。You have to not lose the forest for the trees. You have to get an overview of the languge.
- 找到关键的部分,学习C++的哲学: You have to decide which bits are important and design evolution of C++ if you are into philosophy of it.
- BS:我无法记住所有的,我经常用cpp reference.com(检索)。I use CPP reference.dot a lot because I can’t remember all of function arguements and details.
- BS: 如果痴迷于细节,I would be a very worse programmer because I would be worrying about language and the details all the time.
- BS: Don’t get obsessed with one little fashion how to write code, because so many application areas. 在某些领域,绝对的安全很重要;在另一些领域则不是。你必须决定什么很重要。
很多人只想发财,但是没有耐心了解C++的哲学。 BS: A lot of new programmers, a lot of students have very little patience with philosophy. They just want to get rich.
2.现代C++的值得注意的东西:
- Profiles 安全配置文件C++ Core Guidelines and Microsoft GSL 指南支持工具
BS 谈Profies, “we need them badly”, Pepple want safety and they don’t quite know what safety is. Some people think they can get security out of memory safety, the absence of memory leaks or memory corruption. It’s not that hard to get these things: the range checking and such. But in C++, it’ll have to from profiles and it’ll have to come without breaking a billion of lines of code and programming styles and techniques. I think profiles is the only way I know that can do that. And I did express a certain amount of sadness that we didn’t already have it. That’s very important. I think a lot of people then think philosophical shifts, people think, for instance, ideals of safety are new. They were thery from the beginning. Static type safey, resource safety, and some of the safety fanatics haven’t even gotten to research source safety yet. And we can do much better. Evolution gets us from there to here and it gets us further. I really want profiles up, near the top there.
3.职业建议:
Q:How did you decide what to focus on tronghout your career? BS:
- One is to work with good people and hang out with good people. That’s nice. Sitting on your own is not fun. And working jerks and having to protect your back is not good for your health. And so I’ve always looked out for how to be with interesting and good people. And usually intersting and good because they’re doing interesting things. So you get inspired.
- So the other way of looking at it is I look for something interesting that is fun and useful to work at. I want to build something, I want to do something for people. And those two aspects are closely related.
- So I learned object oriented programming by having a serious number of beers with Kristen Nygaard because he was a vistor to my university, and I was a grad student, so I got into that similarly, I like machine architecture and design machine insructions and such.So basically keep your eyes open, have a board backgroud so that you can take an opportunity when it walks by. What you do and how you get ready to do it, and good solid broad education is what’s underlined(基础教育要扎实且广泛). A Frenchman said fortune favors the prepared mind (Louis Pasteur). This is you have to recognize an opportunity when you see it.
- And things I mentioned briefly and I should probably repeat. I like to do thing that is useful to other people. I don’t want to do a crossword puzzles. 与优秀的人一起工作。与有趣的人一起做有趣的事情。广泛且扎实的基础。做对别人有用的事情。
“I don’t consider anyone a professional if they only know only one language,” BS said, noting that there’s a difference between knowing a language’s syntax and knowing how to write good code. 知道一门语言的语法与写出好代码是有区别的。
C++ fundamental techniques: RAII与不变式
因此我从BS的论文、采访、书籍里面搜集到了他提到的一些C++技术,记录在下面,并且会对每条给出解释和说明。希望这些对其他C++学习者也能有些帮助。注意的是,C++标准库vector,map,set,list等一系列容器里面已经应用了这些技术,如果你不能理解,可以尝试通过阅读标准库的源码来得到更多的领悟。
- 零开销的抽象:机器模型,内联(Inlining),编译时计算。
- 面向对象:classes for separating interfaces from implementations.
- RAII: constructors for establishing invariants, including acquiring resources. destructors for releasing resources,
- 泛型: templates for parameterizing types and algorithms with types
- mapping of source language features to user-defined code specifying their meaning, e.g. [] for
- subscripting, the for-loop, new/delete for construction/destruction on the free store, and the {} lists.
- use of half-open sequences, e.g.
[begin():end()], to define for-loops and general algorithms.
“constructors for establishing invariants, including acquiring resources; destructors for releasing resources,
这句话包含了两种技术:不变式,RAII。
- 对于不变式,BS提到:“我的经验法则是,当且仅当您可以考虑建立类的不变量时,您才应该拥有一个具有接口和隐藏表示的真实类”[BS03,Bill]。不变式用来保证对象有效。比如,你有个Temperature(温度)类,它接受输入的浮点数用来初始化,但是你始终应该在构造函数里面检测温度是否是大于绝对零度(-273.15℃),因为初始化的数字小于绝对零度时,那它必定是错误值,对象是无效的。虽然你完全也可以用成员函数实现这一检测,但不应该那样做,你应该总是在构造函数建议不变式。这样就可以完全避免实例了一个无效的对象。
- RAII,资源申请即初始化。就是说,当你开始申请资源时,表明你正在初始化;反过来,当你在销毁对象时,你应该释放资源。RAII,它把对象的生命周期与资源申请/释放的时间点联系到一起。它看起来不能称为一个技术,无非是在构造函数中申请资源,在析构函数中释放资源。但如果不它单独用一个术语去“显式的”提醒程序员们有这么一个技术存在,那么很多程序员就可能会在各种成员函数中申请资源,因此会造成资源管理的灾难。RAII提醒每个C++程序员,你最好不要在非构造函数中new一个资源,应该总是在构造函数申请,在析构函数释放。如果一个总是能做到RAII,那他基本不可能会写出资源泄漏的代码。(注意:「资源」一词不仅仅是指free store自由存储这一内存资源,也包括了文件描述符、信号量、数据库锁等资源,一定要避免这些资源的泄漏)。
[BS12] B. Stroustrup: Foundations of C++, Texas A&M University. [BS03,Bill] A Conversation with Bjarne Stroustrup, https://www.artima.com/intv/bjarne.html
C++重难点: 1. 类与构造
一个完备的C++类应该实现7个成员函数. A well-defined/complete C++ class typically requires seven member functions, for example:
class X{
public:
X(SomeType); // 'ordinary constructor': create an object from some type
X(); // default constructor
~X(); // destructor: clean up
X(const X&); // copy constructor
X(X&&); // move constructor
X& operator=(const X&); // copy assignment: clean up target and copy
X& operator=(X&&); // move assignment: clean up target and move
};
As a typical, Vector’s move constructor is trivial to define:
class Vector{
Vector(Vector && a) // move constructor
Vector& operator=(Vector&& a); // move assignment
}
Vector::Vector((Vector&& a) // the move constructor implement
:elem{a.elem},
sz{a.sz}
{
a.elem = nullptr;
a.sz = 0;
}
We didn’t really want a copy; we just wanted to get the result out of a function: we wanted to move a Vector rather than copy it. Given that definition, the compiler will choose the move constructor to implement the transfer of th return value out of the funcion. This means that r=x+y+z will involve no copying of Vectors. Instead, Vectors are just moved.
Initially, I was puzzled by the use of a reference as the return type for copy assignment, as I expected local function scope to invalidate it. However, I now understand that it returns a reference to the object pointed to by this. Since the object’s lifetime is managed outside the member function, returning *this by reference is safe and avoids unnecessary copying.
five situations in which an object can be moved or copied:
- As the source of an assignment.
y = x; - As an object initializer.
complex z2 {z1}; - As a function argument.
void test(complex z1) - As a function return value.
- As an exception.
复制和拷贝的分类:
1.从空或者某个值去构造一个新对象。 2.从已有的源对象(复制/移动)去构造一个新对象。 3.将一个已存在的源对象赋值(复制/移动)给另一个已存在的目标对象。
C++ 伪代码:利用移动语义避免拷贝:
Matrix operator+(Matrix&& lhs, const Matrix& rhs) {
lhs.add_data(rhs); // 直接修改左值(临时对象)的内部数据
return std::move(lhs); // 转移所有权
}
C语言的设计哲学是“所见即所得”,C 不希望在 a + b 后面隐藏一个复杂的函数调用(甚至是移动操作)。C的类型系统不支持区分左值和右值的引用,引入它会破坏 C 与汇编之间极其接近的对应关系。
C++ fundamental techniques: Templates
基础知识: Union
- Union的通常用法:节约空间,共享内存。2. 类型双关(type punning)或者说位的重解释(Bit Reinterpretation) 。
在C++中,类型双关容易导致未定义行为,但在C语言中是由实现定义的。
Union的缺陷,struct需要一个type字段维护类型;因此现代C++用std::variant,代码更简洁。
struct Packet {
enum Type { INT, FLOAT, STRING } type; // 必须要维护类型字段
union {
int i;
float f;
char str[32];
} data;
};
void process(const Packet& p) {
switch (p.type) {
case Packet::INT:
std::cout << p.data.i << '\n';
break;
case Packet::FLOAT:
std::cout << p.data.f << '\n';
break;
case Packet::STRING:
std::cout << p.data.str << '\n';
break;
}
}
- 访问字节表示(用 char 数组), 合法的
union ByteView {
float f;
uint32_t i;
unsigned char bytes[4]; // ✅ 合法访问方式
};
void print_bytes(float f) {
ByteView bv;
bv.f = f;
for (int i = 0; i < 4; i++) {
printf("%02X ", bv.bytes[i]);
}
}
- 示例网络协议解析
union IPAddress {
uint32_t addr;
uint8_t octets[4];
};
void print_ip(uint32_t ip) {
IPAddress addr;
addr.addr = ip;
printf("%d.%d.%d.%d\n",
addr.octets[0], addr.octets[1],
addr.octets[2], addr.octets[3]);
}
现代C++20, 优先考虑std::bit_cast, 或者用 std::memcpy (C++17)
void print_ip(uint32_t ip) {
uint8_t octets[4];
std::memcpy(octets, &ip, 4);
printf("%d.%d.%d.%d\n",
octets[0], octets[1], octets[2], octets[3]);
}
快速哈希(位混淆),位的重解释(Bit Reinterpretation)
size_t hash_float(float f) {
return std::bit_cast<uint32_t>(f); // C++20
// 或
uint32_t bits;
std::memcpy(&bits, &f, sizeof(f));
return bits;
}
- IEEE 754 浮点分析
struct FloatParts {
uint32_t mantissa : 23;
uint32_t exponent : 8;
uint32_t sign : 1;
};
union FloatAnalyzer {
float f;
FloatParts parts;
uint32_t bits;
};
void analyze(float f) {
FloatAnalyzer fa;
fa.f = f;
std::cout << "符号: " << fa.parts.sign << '\n';
std::cout << "指数: " << fa.parts.exponent << '\n';
std::cout << "尾数: " << fa.parts.mantissa << '\n';
}
强制类型转换 (uint32_t)f会导致CPU会执行截断操作,但是位的重解释让内存数据原封不动。
21世纪的C++
C++的危机
- 第一,安全性指的不仅仅是内存安全。
- 第二,语言之间的互操作性需求往往会被忽视。
- 第三,语言切换的成本通常会被低估。
why lambda?
[] 的双重作用:
- 告诉编译器”这是 lambda”
- 指定捕获哪些外部变量
[]() { return 42; } // ✅ 不捕获任何变量
[x]() { return x; } // ✅ 捕获变量 x
[&y]() { y++; } // ✅ 按引用捕获 y
[&]() { x++; y++; } // ✅ 按引用捕获所有
[=]() { return x + y; } // ✅ 捕获所有外部变量
[this] // 捕获当前对象,类成员函数中使用
为什么要用lambda,而不是手动定义函数? 或者lambda相比手动定义函数,优点在哪里?
作用1: 可以捕获外部变量
int threshold = 10;
int bonus = 5;
auto check = [threshold, bonus](int value) {
return value > threshold ? value + bonus : value;
};
std::cout << check(15); // 20
std::cout << check(8); // 8
作用2: 代码局部性,不必为了函数内部的代码单独在外部实现一个函数, 更好的模块化。
下述代码,如果把lambda单独实现,就不得不定义一个int g_errorCount全局变量。
void processData(std::vector<int>& data) {
int errorCount = 0;
// 逻辑就在这里,一目了然
std::for_each(data.begin(), data.end(),
[&errorCount](int value) {
if (value < 0) {
errorCount++;
std::cout << "错误值: " << value << '\n';
}
}
);
std::cout << "共 " << errorCount << " 个错误\n";
}
作用3: 每次调用可以不同
auto makeMultiplier(int factor) {
return [factor](int x) { return x * factor; }; // 捕获不同的 factor
}
auto times2 = makeMultiplier(2);
auto times5 = makeMultiplier(5);
std::cout << times2(10); // 20
std::cout << times5(10); // 50
作用4: 支持泛型,而手动函数需要借助模板。
// 泛型 lambda,适用于任何类型
auto print = [](const auto& value) {
std::cout << value << '\n';
};
print(42); // int
print(3.14); // double
print("hello"); // const char*
// 手动函数
template<typename T>
void print(const T& value) {
std::cout << value << '\n';
}
作用5: 闭包(Closure)可以”记住”创建时的环境/状态,而手动函数做不到。
auto makeCounter() {
int count = 0;
return [count]() mutable { // 捕获 count
return ++count;
};
}
auto counter1 = makeCounter();
auto counter2 = makeCounter();
std::cout << counter1(); // 1
std::cout << counter1(); // 2
std::cout << counter2(); // 1 ← 独立的计数器
类型容器 std::variant
- 它是 Union的升级版,是一个类型安全的联合体(Type-safe Union)。与传统的 union 不同,它知道自己当前存储的是哪种类型,并且会自动处理对象的构造和析构,是现代 C++ 处理“多选一”数据的标准方式。
- std::get读取数据,但需要判断类型,如果类型不匹配会抛出异常。 holds_alternative需要用if手动检查。
- std::visit最优雅: 配合 Overloaded ,模式匹配。
基本用法 get+variant:
include <iostream>
#include <variant>
#include <string>
int main() {
// 1. 定义一个可以存放 int 或 string 的变量
std::variant<int, std::string> v;
v = 42; // 现在存储的是 int
v = "Hello Gemini"; // 现在存储的是 string,会自动处理内存
// 2. 读取数据 (使用 std::get)
try {
std::string s = std::get<std::string>(v);
std::cout << "Value: " << s << std::endl;
} catch (const std::bad_variant_access& e) {
std::cout << "类型错误: " << e.what() << std::endl;
}
return 0;
}
优雅的用法,搭配Pack expansion operator。 overloaded作用,简单说,就是对不同类型重载operator()的操作。 把多个 lambda 合并成一个拥有多个重载 operator() 的对象,让 std::visit 能根据类型自动选择调用哪个 lambda。
visit+variant+overloaded:
#include <iostream>
#include <variant>
// 辅助工具:合并多个 lambda
template<class... Ts> // 声明 结构体模板
struct overloaded : Ts... { using Ts::operator()...; }; // 定义 结构体
template<class... Ts> // 声明 推导指引
overloaded(Ts...) -> overloaded<Ts...>; // 定义 推导指引
int main() {
std::variant<int, float, std::string> v = 3.14f;
std::visit(overloaded {
[](int i) { std::cout << "Integer: " << i << std::endl; },
[](float f) { std::cout << "Float: " << f << std::endl; },
[](const std::string& s) { std::cout << "String: " << s << std::endl; }
}, v); // std::visit(访问者, variant对象);
}
应用场景:
- 类型判断
std::variant<int, std::string, std::nullptr_t> data = getData();
std::visit(overloaded {
[](int value) {
std::cout << "收到数字: " << value << '\n';
},
[](const std::string& str) {
std::cout << "收到字符串: " << str << '\n';
},
[](std::nullptr_t) {
std::cout << "收到空值\n";
}
}, data);
- 状态机 (State Machines) 在逻辑设计中,对象往往处于多个状态之一,每个状态携带的数据不同。传统的 struct 会导致内存浪费(所有字段并存),而 variant 能够优雅地表达这种互斥性。
struct Idle {};
struct Connecting { std::string ip; };
struct Connected { int session_id; };
struct Disconnected { std::string reason; };
using ConnectionState = std::variant<Idle, Connecting, Connected, Disconnected>;
// 使用 std::visit 处理不同状态
void handle_state(const ConnectionState& state) {
std::visit(overloaded {
[](const Idle&) { /* 显示初始界面 */ },
[](const Connecting& c) { std::cout << "Connecting to " << c.ip; },
[](const Connected& c) { std::cout << "Session: " << c.session_id; },
[](const Disconnected& d) { std::cerr << "Error: " << d.reason; }
}, state);
}
- 类型转换
std::variant<int, double, std::string> v = 42;
std::string str = std::visit(overloaded {
[](int i) { return std::to_string(i); },
[](double d) { return std::to_string(d); },
[](const std::string& s) { return s; }
}, v);
C语言可以用 union做类型转换,在C++中属于未定义行为。
现代 C++支持 std::bit_cast 进行安全的位转换,memcpy。
- 静态多态,避免昂贵的“继承+虚函数”的开销。
如果你有一组类型(如圆、方、长方形),虽然它们有共同行为,但你不想使用动态内存分配(new)和虚函数表(vtable)带来的开销,variant 是实现静态多态的利器。
对比: 虚函数需要通过指针调用,可能有缓存缺失(Cache Miss);variant 存储在连续内存中,配合 std::visit 性能极高。
struct Circle { double radius; };
struct Square { double side; };
using Shape = std::variant<Circle, Square>;
double get_area(const Shape& s) {
return std::visit(overloaded {
[](const Circle& c) { return 3.14 * c.radius * c.radius; },
[](const Square& q) { return q.side * q.side; }
}, s);
}
- 解析异构数据(如 JSON/配置文件)
在处理 JSON 时,一个字段的值可能是 int、string、bool 或 double。variant 是描述这种“不确定但有限”类型的完美选择。
using JsonValue = std::variant<std::nullptr_t, bool, int, double, std::string>;
// 一个 key 对应一个 JsonValue
std::map<std::string, JsonValue> config; // 定义一个map类型
config["port"] = 8080;
config["server"] = "localhost";
config["debug"] = true;
- 健壮的错误处理 (替代错误码)
在函数可能返回结果也可能返回错误时,传统的做法是返回 -1 或指针,但这往往不直观。variant 可以像函数式语言(如 Rust 的 Result)那样清晰地表达结果。
struct Success { std::vector<uint8_t> data; };
struct Error { int code; std::string message; };
using FetchResult = std::variant<Success, Error>;
FetchResult download_data() {
if (network_ok) return Success{...};
else return Error{404, "Not Found"};
}
volatile
int value = 10;
int test() {
int a = value;
int b = value;
int c = value;
return a + b + c;
}
无 volatile 的汇编(-O2)
test():
mov eax, DWORD PTR value[rip] ; 读取一次
lea eax, [rax+rax*2] ; eax = eax * 3(优化!)
ret
编译器优化:只读取内存一次, 计算 value * 3
有 volatile 的汇编
test():
mov eax, DWORD PTR value[rip] ; 读取第一次
mov edx, DWORD PTR value[rip] ; 读取第二次
add eax, edx
mov edx, DWORD PTR value[rip] ; 读取第三次
add eax, edx
ret
volatile 不保证原子性, 不保证内存顺序,不同步缓存。
编译配置
Jetbrains Clion
编译器选项(添加import支持):
-std=c++23 -fmodules-ts
Cmake配置
# C++设置
set(CMAKE_CXX_STANDARD 23)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(CMAKE_CXX_SCAN_FOR_MODULES ON) # 开启模块扫描
Qt6 示例
#include <QApplication>
#include <QWidget>
#include <QPushButton>
#include <QVBoxLayout>
#include <QLabel>
int main(int argc, char *argv[]) {
QApplication a(argc, argv);
// 1. 创建主窗口和布局
QWidget window;
window.setWindowTitle("Qt Signal Slot Example");
QVBoxLayout *layout = new QVBoxLayout(&window);
// 2. 创建显示文字的标签
QLabel *label = new QLabel("Waiting...");
label->setAlignment(Qt::AlignCenter); // 文字居中
layout->addWidget(label);
// 3. 创建按钮
QPushButton *btn1 = new QPushButton("Click Me1");
QPushButton *btn2 = new QPushButton("Click Me2");
layout->addWidget(btn1);
layout->addWidget(btn2);
// 4. 连接信号与槽 (使用 Lambda 表达式,C++ 开发者最爱的现代写法)
// 语法:connect(发信者, 信号, 接收者, 逻辑处理)
QObject::connect(btn1, &QPushButton::clicked, [label]() {
label->setText("点击1 ok");
});
QObject::connect(btn2, &QPushButton::clicked, [label]() {
label->setText("点击2 ok");
});
window.show();
return a.exec();
}
依赖和编译
sudo apt install qt6-base-dev qt6-declarative-dev
// 编译
c++ /home/code/example/example.cpp -o example $(pkg-config --cflags --libs Qt6Widgets) -fPIC
Qt的核心概念:
- Meta-Object Compiler , 提供反射,Qt 需要额外的元信息(信号、槽、属性等)
- 所有 Qt 对象的基类。QObject宏, 启用 Qt 的元对象系统 ,支持信号与槽,支持属性系统。
- Qt最强大的特性:信号与槽(Signals & Slots),对象间通信的优雅机制。
connect(sender, &Sender::signal,
receiver, &Receiver::slot);
Rust programming
Core Concepts
1. Ownership and Borrowing
- Each value has exactly ONE owner variable.
- When the owner goes out of scope, the value is dropped (freed).
- Ownership can be transferred (moved) but not
duplicated(unlessClone).
- 在 C++ 中,如果你写
std::string s2 = s1;,编译器默认会调用拷贝构造函数,在堆上开辟一块新内存,把数据原封不动地复制一遍(深拷贝)。如果这个字符串有 100MB,这行代码就会默默卡住一阵子,容易引发难以察觉的性能瓶颈。 - 在 Python 中,s2 = s1 只是多了一个引用指向同一个对象(引用计数 +1),这又带来了多线程下需要 GIL 保护的麻烦。
- Rust 的态度是: 既不允许像 Python 那样隐式共享(容易导致数据竞争),也不允许像 C++ 那样隐式深拷贝(隐藏性能损耗)。因此,默认情况下,数据是“不可复制(not duplicated)”的。
clone = explict deep copy
Golang Programming
基本知识
基本语法:
- Golang的defer:LIFO,后进先出,栈的数据结构。弄清入栈顺序。defer注意函数返回前的参数的状态。
- uintptr vs unsafe.Pointer (指针)。uintptr是整数类型,可算数运算;后者是指针类型,不能算数运算。 GC会忽略uitptr, 后者gc会跟踪它指向的对象。这两个类型可以相互转换,实际应用场景主要是Cgo交互的时候。
- new(T)与make: new 任意类型分配零值,内存并返回 *T 指针; make 仅用于 Slice、Map、Channel 的初始化,返回引用类型。
- init() 在 main() 之前调用。注册驱动, 加载配置文件,初始化全局变量。它很强,但不要使用。执行顺序有时难以控制,容易引入隐藏 bug。
- 结构体比较规则? 只有当所有成员都可比较(如基本类型)时,结构体才可以用 == 比较。
- 判断一个接口变量是否为 nil?接口由 (type, value) 组成,只有当类型和值都为 nil 时,接口才等于 nil。
基本哲学:
- golang 重载: golang不支持重载,每个函数都必须要唯一. 替代的方式是:泛型和接口。
- Go 传参是传值还是传引用? 全都是传值(Pass by Value)。Slice Map Chan 但引用类型的值是引用,所以修改底层数据会影响原变量。
- Go 的强制类型转换语法? T(v)。Go 不支持隐式转换,即使是 int32 转 int64 也必须强转。
- Go 语言没有传统的“继承”(inheritance)概念,也没有 class 关键字。Go 鼓励组合优于继承(composition over inheritance)的设计哲学。结构体嵌入(embedding)可以实现类似继承的效果。指针嵌入可以修改父类。
基本特性:
- Goroutine 是用户态轻量级线程。区别:栈大小(2KB 起步 vs 线程数 MB)、切换开销(用户态切换 vs 内核态切换)。
- Golang 的逃逸分析(Escape Analysis),编译器决定变量分配在栈上还是堆上。如果变量在函数外部被引用,则会逃逸到堆。
- Map 是线程安全的吗? 答案:不是。并发读写会 panic。并发安全需使用 sync.Map 或加锁
- 比空接口更好的方式是泛型。空接口 interface{}可以存储任意类型的值。Go 1.18 之后可以用 any 代替,any 是 interface{} 的类型别名 。. interface{} 失去了类型信息。 需要做类型判断, 才能用。泛型 类似C++的模板, 零运行时开销(编译期单态化)。 interface{} 是“运行时多态”,泛型是“编译时多态”。如果你在写容器、算法、工具库,优先考虑泛型;如果只是临时传递未知类型的数据(如配置解析),any 依然有用武之地。
- GMP 模型:G(Goroutine):用户级轻量级协程。M(Machine):OS 线程(真正被 CPU 执行的实体) P(Processor):逻辑处理器,包含 Goroutine 队列,M 必须绑定一个 P 才能运行 G。默认情况下,GOMAXPROCS = CPU 核心数(Go 1.5+),意味着 Go runtime 会启动多个 OS 线程(M),每个线程绑定一个 P,并行执行多个 Goroutine。P 负责连接 G 和 M,实现多核调度。
代码规范:
- 优先考虑复用对象,而不是用make重新分配内存。
- 尽量预分配切片的容量,用空间换时间,避免运行时扩容。
- 理解值类型和指针的权衡
When creating Go packages, I try to follow these rules:
- keep the package name as simple as possible, if possible in a single word.
- keep it all lowercase, with no separation.
- keep the package name singular.
- For each package, I usually have a .go file with the same name, declaring the main interface or struct of the package.
- For non-package folders, it is ok to have a multi-word name, but separate them by -, not _.
Link: How I organize (most of) my Go microservices
有趣的部分
const和iota
- const 约定一个常量,运行时不能修改; 修饰表达式,支持编译时计算的概念。
- const存储的常用,它们不占用运行时可写内存(如栈或堆),而是放在只读数据段(.rodata)或代码段(.text)中。程序运行时尝试修改会引发段错误(segmentation fault)或 panic。
- int、float、bool 数值常量,直接是立即数。不会有分配额外的内存。 字符串常量或者数组或结构体,.rodata 数据段里面。
- iota 是常量计数器,在 const 块中每新增一行其值自增 1。 跳过 0 值(常见做法)
- 不建议在非 const 上下文中使用 iota(编译错误)。iota 是 Go 中最优雅的枚举生成器,没有 enum 关键字,但用 const + iota 就能实现干净、可读的枚举。
const (
Sunday = iota // 0
Monday // 1
Tuesday // 2
Wednesday // 3
Thursday // 4
Friday // 5
Saturday // 6
)
const (
_ = iota // 0(丢弃,不使用)
KB uint64 = 1 << (10 * iota) // 1 << 10 = 1024
MB // 1 << 20 = 1048576
GB // 1 << 30 = 1073741824
TB // 1 << 40 = 1099511627776
)
const (
FlagNone = 0
FlagRead = 1 << iota // 1 << 1 = 2
FlagWrite // 1 << 2 = 4
FlagExec // 1 << 3 = 8
FlagDelete // 1 << 4 = 16
)
Slice的底层结构与扩容:
一个结构体,包含:指向底层数组的指针、长度(len)、容量(cap)。
type SliceHeader struct {
Data uintptr // 指向底层数组的指针
Len int // 当前长度
Cap int // 容量(从 Data 开始到底层数组末尾的元素个数)
}
Data:指向底层数组(array)的起始地址。 Len:当前 slice 包含的有效元素个数(0 <= len <= cap)。 Cap:从 Data 开始到底层数组末尾的总容量(决定了还能追加多少元素而不重新分配)。
arr := [6]int{1, 2, 3, 4, 5, 6}
s1 := arr[1:4] // [2,3,4], len=3, cap=5
s2 := s1[1:3] // [3,4], len=2, cap=4
// s1 和 s2 共享 arr 的内存
Slice 不是数组,而是对底层数组的一个视图(view)。 多个 slice 可以共享同一个底层数组。 修改一个 slice 的元素,可能影响其他共享底层数组的 slice。
切片操作(slicing)不会重新生成slice。 Data 指向原数组偏移位置,Len=2, Cap=原Cap - 起始索引。
Slice append 扩容机制
runtime/growslice 代码的实现
Go 1.18 以后:容量 < 256 时翻倍; > 256 时按 $(oldcap + 3*256) / 4 增长。
扩容会有开销: 分配新数组,拷贝旧数据,更新 Data 指针
Map 的底层实现:哈希表 + 桶(数组)
答案:基于哈希表(Hash Table),使用数组+链表结构,通过 Bucket(桶) 存储 kv 对。
type hmap struct {
count int // 元素个数(len(map))
flags uint8 // 状态标志(如是否正在写入)
B uint8 // 桶的数量为 2^B(即 bucket 数量 = 1 << B)
noverflow uint16 // 溢出桶计数(近似)
hash0 uint32 // 哈希种子(用于防哈希碰撞攻击)
buckets unsafe.Pointer // 指向主桶数组([]bmap)
oldbuckets unsafe.Pointer // 扩容时指向旧桶(渐进式迁移用)
nevacuate uintptr // 已迁移的桶索引(用于增量 rehash)
extra *mapextra // 可选字段(溢出桶等)
}
bmap 结构体
type bmap struct {
topbits [8]uint8 // 高 8 位哈希值(用于快速比较)
keys [8]KeyType // 8 个 key
values [8]ValueType // 8 个 value
pad [7]byte // 对齐填充(实际没有,仅为示意)
overflow unsafe.Pointer // 指向溢出桶(当一个桶放不下时)
}
buckets 是指针,指向bmap结构的数组。 oldbuckets 指向上个bmap,
每个桶,有8个键值对。
固定桶大小(8 元素) → 平衡 cache 局部性与内存浪费; tophash 快速过滤 → 减少 key 比较次数; 渐进式扩容 → 避免长时间停顿; 运行时随机哈希种子 → 防止 Hash DoS; 非并发安全 → 明确设计取舍,把控制权交给用户。
- ✅ 同一个桶内的 8 个 key 是连续的
- ❌ 跨桶的 key 不连续
- ❌ 整体上 key 是“随机打散”的,无法保证遍历时内存地址连续
缓存局部性如何?
- 时间局部性(Temporal Locality):✅ 较好(热点数据会被频繁访问)
- 空间局部性(Spatial Locality):❌ 较差 – CPU 缓存行(Cache Line,通常 64 字节)加载时,希望附近数据也被用到 – 但 map 的 key 分散在各处,一次缓存加载可能只用到 1 个 key – 遍历 map 时,CPU 缓存命中率低 → 性能不如 slice/array
Map 的哈希冲突如何解决?
“链地址法(Separate Chaining)” 结合 “桶内线性探测 + 溢出桶” 的混合策略来解决。这不是传统的“每个桶挂一个链表”,而是一种高度优化的、基于固定大小桶(bucket)的结构。
Channel 的底层结构和用法
Go 的哲学是: Don’t communicate by sharing memory; share memory by communicating.
Channel 的底层结构:一个循环队列(环形数组),以及发送等待队列和接收等待队列。
- 缓冲区(buf)buf 指向一个环形队列(circular buffer)。
- 等待队列(recvq / sendq):当没有数据可读时,试图接收的 Goroutine 会被挂起并加入此队列。当缓冲区满或无缓冲 Channel 无人接收时,试图发送的 Goroutine 会被挂起并加入此队列。 这些队列是 FIFO 双向链表(waitq 结构),保证公平性。
- 所有对 Channel 的操作(send/receive/close)都受同一个 mutex 保护。
- closed 标志。关闭 Channel 后,closed = 1。 关闭后, 可读不可写
| 操作 | 含义 |
|---|---|
ch <- true |
发送:把 true 发送到通道 ch |
value := <-ch |
接收:从通道 ch 接收一个值,赋给 value |
<-ch |
只接收,不使用值(常用于同步) |
chnnel 用于gorountine之间数据的接受和发送。
发送和接收必须严格同步(一方阻塞直到另一方就绪)。
发送和接收都是阻塞操作:
- 发送方会等,直到有接收方准备好了;
- 接收方会等,直到有发送方发来了数据。
package main
import "fmt"
func main() {
done := make(chan bool) // 创建一个 bool 类型的 channel
go func() {
fmt.Println("子任务开始...")
// 模拟一些工作
fmt.Println("子任务完成!")
done <- true // 通知主程序:我干完了!
}()
<-done // 主程序在这里等待,直到收到信号
fmt.Println("主程序继续执行")
}
无缓冲和有缓冲 Channel 的区别? 答案:无缓冲是同步的(发送须等待接收);有缓冲是异步的,直到缓冲区满才阻塞。
一个已关闭的 Channel 进行读写会怎样? 答案:读:读完剩余数据后返回零值;写:直接 panic;再次关闭:直接 panic。
如何优雅地关闭 Channel? 答案: 原则:由生产者关闭,或者使用 sync.Once 确保只关一次。 生产者关闭,能确保不会再次写入。
The behavior of select
- Rule 1: Execute whichever is ready first (Blocking wait).
- Rule 2: If multiple are ready simultaneously, it uses a “random coin flip” strategy (Fairness).
- Rule 3: If there is a default case, it never waits (Non-blocking).
核心技术 (抽象)
- 并发: Channel 协程通信, contex 并发控制
- 接口 (抽象设计)
1. Accept interfaces, return concrete types
“The bigger the interface, the weaker the abstraction.” — Rob Pike
接口的注意事项:
- 接口由使用者定义(The consumer defines the interface)
- 接口要小(Keep Interfaces Small and Focused ), 一个接口只做一件事(Single Responsibility 原则)
- Use Composition to Build More Complex Interfaces
- 函数参数用接口,返回值用具体类型.。
One of the most famous proverbs in Go: “Accept interfaces, return structs.” Returning structs is the default because it forces callers to rely on concrete implementations rather than abstractions they might not need. It also allows you to add new methods to your struct later without breaking existing code.
接受接口返回接口最大区别,前者具有良好的解耦,后者返回了整个实现,对象(struct)和它的方法。
- The small interface:
// Go standard library: src/io/io.go
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
type Closer interface {
Close() error
}
// interface embedding
type ReadWriter interface {
Reader
Writer
}
type ReadWriteCloser interface {
Reader
Writer
Closer
}
os.File、网络连接、HTTP 响应体http.Response.Body 实现了其中的部分接口。
net/http/response.go
// body turns a Reader into a ReadCloser.
// Close ensures that the body has been fully read
// and then reads the trailer if necessary.
type body struct {
src io.Reader
hdr any // non-nil (Response or Request) value means read trailer
r *bufio.Reader // underlying wire-format reader for the trailer
closing bool // is the connection to be closed after reading body?
doEarlyClose bool // whether Close should stop early
mu sync.Mutex // guards following, and calls to Read and Close
sawEOF bool
closed bool
earlyClose bool // Close called and we didn't read to the end of src
onHitEOF func() // if non-nil, func to call when EOF is Read
}
理解接口的本质:
接口的语法很简单,看起来很容易学会,但它的哲学不是那么容易理解的。它不同于 int, bool, struct这些编译时就确定的类型, 接口只要求 某个类型实现了接口中的方法,就属于这种接口类型。这是种运行时多态。
Best Practice : Define Interfaces Where They Are Used
我定义,我使用,你实现: 实现方可以采用值接收者,也可以是指针接收者。
// consumer package
type FileReader interface {
ReadFile(filePath string) ([]byte, error)
}
func ProcessFile(reader FileReader, filePath string) ([]byte, error) {
return reader.ReadFile(filePath)
}
// implementation package
type LocalFileReader struct {}
func (lfr LocalFileReader) ReadFile(filePath string) ([]byte, error) {
// Implementation for reading a file from local storage
}
When to return interfaces?
-
The Factory Pattern (Multiple Implementations)
-
Information Hiding (Strict Encapsulation)
Sometimes you have a complex struct with many exported fields and methods, but you only want to expose a very specific subset of its capabilities to the caller. Returning an interface acts as a contract that restricts what the caller can do, protecting your internal state.
// A complex struct with many features
type UserSession struct {
ID string
Token string
IsActive bool
}
func (s *UserSession) GetID() string { return s.ID }
func (s *UserSession) Destroy() { s.IsActive = false }
// ReadOnlySession only allows getting the ID
type ReadOnlySession interface {
GetID() string
}
// Return the interface to hide the Destroy method and fields
func GetSession(id string) ReadOnlySession {
return &UserSession{ID: id, IsActive: true}
}
- Returning Standard Library Interfaces
You likely already return interfaces all the time without thinking about it! The built-in error type is an interface. It is also highly idiomatic to return standard library interfaces like io.Reader or io.Writer when writing generic utility functions that wrap other streams of data.
import (
"bytes"
"io"
)
// Return io.Reader so the caller can read the data easily
func GetGreeting() io.Reader {
return bytes.NewBufferString("Hello, World!")
}
Summary Rule of Thumb:
Stick to returning structs by default. Only return an interface if you have a concrete reason to hide the underlying type (e.g., swapping out implementations, wrapping standard library behaviors, or strictly locking down the API surface).
Breaking Down Large Interfaces
“The bigger the interface, the weaker the abstraction” —— Rob Pike
Example 1 : Golang: Breaking Down Large Interfaces with Embedding Golang
// database package
type DBInterface interface {
CreateItem(Item) (*Item, error)
}
type DB struct {
*sql.DB
}
func (db *DB) CreateItem(item Item) (*Item, error) {
query := `INSERT INTO Table_Items(Name) VALUES(@itemName)`
db.Query(query, sql.Named("itemName", item.Name))
return &item, nil
}
type MockDB struct {}
func (db *MockDB) CreateItem(item Item) (*Item, error) {
i := Item{Name: "Foo"}
return &i, nil
}
// shopping cart package - import database package
type Cart struct {
DB db.DBInterface
}
// Live implementation
db := db.DB{*sql.DB}
cartService := Cart{DB: &db}
// Mock out db when testing the cart service
db := db.MockDB{}
cartService := Cart{DB: &mockDB}
Before:
// package db
type MyDB interface {
CreateThingOne(ThingOne) (ThingOne, error)
FindThingOne(string) (ThingOne, error)
UpdateThingOne(ThingOne) (ThingOne, error)
DeleteThingOne(string) error
CreateThingTwo(ThingTwo) (ThingTwo, error)
FindThingTwo(string) (ThingTwo, error)
UpdateThingTwo(ThingTwo) (ThingTwo, error)
DeleteThingTwo(string) error
}
// package foo
type FooService struct {
DB db.MyDB
}
One way to get around this problem is to split our database into sub-packages by entity.
After:
// package db/thing_one_db
type ThingOneDB interface {
CreateThingOne(ThingOne) (ThingOne, error)
FindThingOne(string) (ThingOne, error)
UpdateThingOne(ThingOne) (ThingOne, error)
DeleteThingOne(string) error
}
// package db/thing_two_db
type ThingTwoDB interface {
CreateThingTwo(ThingTwo) (ThingTwo, error)
FindThingTwo(string) (ThingTwo, error)
UpdateThingTwo(ThingTwo) (ThingTwo, error)
DeleteThingTwo(string) error
}
// package foo
type FooService struct {
ThingOneDB thing_one_db.ThingOneDB
ThingTwoDB thing_two_db.ThingTwoDB
}
Improved Solution: Embedding This is great because Go’s interface type can absolutely be embedded. Applying this concept to our problem looks something like this:
// package db
type MyDB struct {
ThingOneDB
ThingTwoDB
}
type ThingOneDB interface {
CreateThingOne(ThingOne) (ThingOne, error)
FindThingOne(string) (ThingOne, error)
UpdateThingOne(ThingOne) (ThingOne, error)
DeleteThingOne(string) error
}
type ThingTwoDB interface {
CreateThingTwo(ThingTwo) (ThingTwo, error)
FindThingTwo(string) (ThingTwo, error)
UpdateThingTwo(ThingTwo) (ThingTwo, error)
DeleteThingTwo(string) error
}
// package foo
type FooService struct {
DB db.MyDB
}
// package main
func main() {
database := db.MyDB{ThingOneDB: db.ThingOneDBImpl{}}
fooService := FooService{
DB: database,
}
}
The difference here is that we are now able to import the database struct type which consists of embedded interfaces instead of importing one giant interface.
Example 2:
type ProtocolDriver interface {
Initialize(sdk DeviceServiceSDK) error // Lifecycle Management
Start() error
Stop(force bool) error
HandleReadCommands(...) error // cmd handle
HandleWriteCommands(...) error
AddDevice(...) error // device event
UpdateDevice(...) error
RemoveDevice(...) error
}
Disadvantages: Forces the implementation of irrelevant methods
Better practice:
// Responsibility 1: Lifecycle Management
type Lifecycle interface {
Initialize(sdk DeviceServiceSDK) error
Start() error
Stop(force bool) error
}
// Responsibility 2: Command Handling (Read-only devices can implement only Reader)
type CommandReader interface {
HandleReadCommands(
deviceName string,
protocols map[string]ProtocolProperties,
reqs []CommandRequest,
) ([]*CommandValue, error)
}
type CommandWriter interface {
HandleWriteCommands(
deviceName string,
protocols map[string]ProtocolProperties,
reqs []CommandRequest,
params []*CommandValue,
) error
}
// Responsibility 3: Device Events (Optional, isolated with a separate interface)
type DeviceWatcher interface {
AddDevice(deviceName string, protocols map[string]ProtocolProperties, adminState AdminState) error
UpdateDevice(deviceName string, protocols map[string]ProtocolProperties, adminState AdminState) error
RemoveDevice(deviceName string, protocols map[string]ProtocolProperties) error
}
// The SDK internally calls as needed via type assertions, rather than requiring full implementation
type ProtocolDriver interface {
Lifecycle
CommandReader
CommandWriter
}
2. Channel: 手搓消息队列
生产者消费者模型
func producer(ch chan<- int) {
defer close(ch) // 发完数据后关闭
ch <- 1
ch <- 2
}
func main() {
ch := make(chan int)
go producer(ch)
for v := range ch { // 自动在 channel 关闭后退出循环
fmt.Println(v)
}
}
手搓消息中间件
- 手搓一个消息队列v1,用go channel做Broker ```go package main
import ( “log” “sync” “time” )
// Message 消息结构体 type Message struct { ID int Content string Timestamp time.Time }
// SimpleBroker 简单的消息代理 type SimpleBroker struct { messages chan Message mu sync.RWMutex }
// NewSimpleBroker 构造 func NewSimpleBroker() *SimpleBroker { return &SimpleBroker{ messages: make(chan Message, 100), // 缓冲 100 条消息 } }
// Publish 发布消息 func (b *SimpleBroker) Publish(msg Message) { b.messages <- msg log.Printf(“[Broker] 收到消息: ID=%d, Content=%s\n”, msg.ID, msg.Content) }
// Subscribe 订阅消息 func (b *SimpleBroker) Subscribe() <-chan Message { return b.messages }
// Producer 生产者 type Producer struct { broker *SimpleBroker }
// NewProducer 创建生产者 func NewProducer(broker *SimpleBroker) *Producer { return &Producer{broker: broker} }
// Start 启动生产者 func (p *Producer) Start() { go func() { counter := 1 ticker := time.NewTicker(5 * time.Second) defer ticker.Stop()
for range ticker.C {
msg := Message{
ID: counter,
Content: "hello",
Timestamp: time.Now(),
}
p.broker.Publish(msg)
log.Printf("✓ [Producer] 发送消息成功: ID=%d, Content=%s\n", msg.ID, msg.Content)
counter++
}
}() }
// Consumer 消费者 type Consumer struct { id int broker *SimpleBroker }
// NewConsumer 创建消费者 func NewConsumer(id int, broker *SimpleBroker) *Consumer { return &Consumer{ id: id, broker: broker, } }
// Start 启动消费者 func (c *Consumer) Start() { go func() { msgChan := c.broker.Subscribe()
for msg := range msgChan {
log.Printf("★ [Consumer-%d] 接收到消息: ID=%d, Content=%s, Timestamp=%s\n",
c.id, msg.ID, msg.Content, msg.Timestamp.Format("15:04:05"))
}
}() }
func main() { // 创建 Broker broker := NewSimpleBroker() log.Println(“✓ Broker 已创建”)
// 创建生产者
producer := NewProducer(broker)
producer.Start()
log.Println("✓ Producer 已启动,将每 5 秒发送一条消息")
// 创建消费者(可以创建多个)
consumer1 := NewConsumer(1, broker)
consumer1.Start()
log.Println("✓ Consumer-1 已启动")
// 可选:创建第二个消费者
consumer2 := NewConsumer(2, broker)
consumer2.Start()
log.Println("✓ Consumer-2 已启动")
// 保持程序运行
select {} } ```
- v2. 分布式,使用http协议 ```go package main
import ( “bytes” “encoding/json” “fmt” “log” “net/http” “time” )
// ========================================== // 公共部分:数据协议 (Protocol) // ==========================================
// Message 消息结构体,JSON 用于网络传输
type Message struct {
ID int json:"id"
Content string json:"content"
}
// ========================================== // 机器 A:Broker (服务端) // ==========================================
type BrokerServer struct { queue chan Message // 内部消息队列 }
func NewBrokerServer() *BrokerServer { return &BrokerServer{ // 创建一个带缓冲的 channel,模拟消息队列 queue: make(chan Message, 100), } }
// 处理生产者请求 (POST /publish) func (b *BrokerServer) handlePublish(w http.ResponseWriter, r *http.Request) { if r.Method != http.MethodPost { http.Error(w, “只支持 POST 方法”, http.StatusMethodNotAllowed) return }
var msg Message
// 1. 从网络流中解析 JSON
if err := json.NewDecoder(r.Body).Decode(&msg); err != nil {
http.Error(w, "JSON 格式错误", http.StatusBadRequest)
return
}
// 2. 尝试写入队列
select {
case b.queue <- msg:
log.Printf("[Broker - 8080] 收到并存入队列: ID=%d", msg.ID)
w.WriteHeader(http.StatusOK)
w.Write([]byte("Success"))
default:
log.Printf("[Broker - 8080] 队列已满,丢弃消息: ID=%d", msg.ID)
http.Error(w, "队列已满", http.StatusServiceUnavailable)
} }
// 处理消费者请求 (GET /consume) func (b *BrokerServer) handleConsume(w http.ResponseWriter, r *http.Request) { if r.Method != http.MethodGet { http.Error(w, “只支持 GET 方法”, http.StatusMethodNotAllowed) return }
// 1. 尝试从队列读取
select {
case msg := <-b.queue:
// 2. 将消息序列化为 JSON 返回网络
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(msg)
log.Printf("[Broker - 8080] 消息已投递给消费者: ID=%d", msg.ID)
default:
// 队列为空,返回 204 No Content
w.WriteHeader(http.StatusNoContent)
} }
// StartBroker 启动 Broker 的 HTTP 服务 func StartBroker() { broker := NewBrokerServer()
// 注册路由
mux := http.NewServeMux()
mux.HandleFunc("/publish", broker.handlePublish)
mux.HandleFunc("/consume", broker.handleConsume)
log.Println(">>> [Machine A] Broker 服务启动,监听 :8080 端口...")
// 这是一个阻塞调用,我们在 main 中用 go routine 启动它
if err := http.ListenAndServe(":8080", mux); err != nil {
log.Fatalf("Broker 启动失败: %v", err)
} }
// ========================================== // 机器 B:Producer (客户端) // ==========================================
func StartProducer() { log.Println(“»> [Machine B] Producer 启动…”) brokerURL := “http://localhost:8080/publish” counter := 1
for {
// 1. 构造消息
msg := Message{
ID: counter,
Content: fmt.Sprintf("来自机器 B 的订单 #%d", counter),
}
// 2. 序列化为 JSON
jsonData, _ := json.Marshal(msg)
// 3. 发起 HTTP POST 请求 (模拟跨机器网络调用)
resp, err := http.Post(brokerURL, "application/json", bytes.NewBuffer(jsonData))
if err != nil {
log.Printf("!!! [Producer] 连接 Broker 失败: %v", err)
} else {
// 务必关闭 Body
resp.Body.Close()
if resp.StatusCode == http.StatusOK {
log.Printf("✓ [Producer] 发送成功: ID=%d", msg.ID)
} else {
log.Printf("x [Producer] 发送被拒绝, 状态码: %d", resp.StatusCode)
}
}
counter++
// 模拟每 2 秒生产一条
time.Sleep(2 * time.Second)
} }
// ========================================== // 机器 C:Consumer (客户端) // ==========================================
func StartConsumer(clientID int) { log.Printf(“»> [Machine C-%d] Consumer 启动…”, clientID) brokerURL := “http://localhost:8080/consume”
client := &http.Client{Timeout: 5 * time.Second}
for {
// 1. 发起 HTTP GET 请求 (轮询)
resp, err := client.Get(brokerURL)
if err != nil {
log.Printf("!!! [Consumer-%d] 连接 Broker 失败: %v", clientID, err)
time.Sleep(1 * time.Second)
continue
}
// 2. 处理响应
if resp.StatusCode == http.StatusOK {
var msg Message
if err := json.NewDecoder(resp.Body).Decode(&msg); err == nil {
log.Printf("★ [Consumer-%d] 消费成功: ID=%d, 内容: %s", clientID, msg.ID, msg.Content)
}
} else if resp.StatusCode == http.StatusNoContent {
// 队列为空,没有新消息
// log.Printf("[Consumer-%d] 暂无消息...", clientID)
}
resp.Body.Close()
// 模拟轮询间隔 (防止死循环把 CPU 跑满)
time.Sleep(500 * time.Millisecond)
} }
// ========================================== // Main 入口:模拟整个分布式环境 // ==========================================
func main() { // 1. 启动 Broker (模拟在机器 A) // 使用 go routine 启动,因为它会阻塞监听端口 go StartBroker()
// 给 Broker 一点时间启动
time.Sleep(1 * time.Second)
fmt.Println("-------------------------------------------------")
// 2. 启动 Consumer (模拟在机器 C)
// 启动一个消费者
go StartConsumer(1)
// 3. 启动 Producer (模拟在机器 B)
// 启动生产者
go StartProducer()
// 4. 阻塞主进程,防止程序退出
select {} } ```
v3, gRPC通信。
syntax = "proto3";
package main;
// 这是一个配置,让生成的 Go 代码属于 main 包,方便你在一个文件夹里跑
option go_package = "./;main";
// 1. 定义消息结构
message Message {
int32 id = 1;
string content = 2;
}
// 空请求,用于 Subscribe 时(也可以传 ConsumerID)
message SubscriptionRequest {
int32 id = 1;
}
// 简单的响应
message PublishResponse {
bool success = 1;
string msg = 2;
}
// 2. 定义服务接口
service BrokerService {
// 生产者调用:单次发送
rpc Publish (Message) returns (PublishResponse);
// 消费者调用:服务端流模式 (Server Streaming)
// 消费者建立一次连接,Broker 会源源不断地把 Message 推过来
rpc Subscribe (SubscriptionRequest) returns (stream Message);
}
contex 处理并发控制。
超时控制,然后传递元数据(Value)。
func main() {
// 创建一个 2 秒后自动过期的 Context
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel() // 别忘了释放资源
go doSomething(ctx)
// 等待结果
<-ctx.Done()
fmt.Println("主程序退出:", ctx.Err())
}
func doSomething(ctx context.Context) {
for {
select {
case <-ctx.Done(): // 收到“停止”信号
fmt.Println("协程:收到指令,停止工作")
return
default:
fmt.Println("协程:正在搬砖...")
time.Sleep(500 * time.Millisecond)
}
}
}
- 不要把 Context 放在结构体里:它应该作为函数的第一个参数显式传递,通常起名为 ctx。
- 不要传递 nil:如果你不知道传什么,传 context.TODO()。
- 它是线程安全的:你可以在无数个协程里传递同一个 ctx,安全地监听它的信号。
- 层级传递:当你基于一个父 ctx 创建子 ctx 时(比如 WithTimeout),如果父级被取消,所有的子级也会跟着被取消。
Graceful Shutdown
The old method (the traditional three-step process):
q := make(chan os.Signal, 1)
// signal.Notify accept (Send-Only Channel, Variadic Parameter: Ctrl+c or kill pid)
signal.Notify(q, syscall.SIGINT, syscall.SIGTERM)
<-q
The underlying mechanism of signal.Notify:
- Registration: When signal.Notify is called, it adds the current channel into the Signal Registry.
- OS Interrupt: When an interrupt occurs (such as pressing Ctrl+C on the keyboard), the operating system sends a real hardware/system interrupt to the Go process and hands over control to the Go runtime.
- Dispatch: The Go runtime checks the global registry, finds all the channels that have subscribed to this specific signal, and iterates through them to send the signal using Non-blocking Dispatch.
Conceptual code:
// Conceptual code of what Notify does internally
func Notify(c chan<- os.Signal, sig ...os.Signal) {
// If no specific signals are provided, listen to all
if len(sig) == 0 {
// Register channel 'c' for all signals
// ...
return
}
// Loop through the provided signals
for _, s := range sig {
// Add the channel 'c' to the list of listeners for signal 's'
// Go runtime uses a global struct to store these mappings
add(c, s)
}
}
// Inside Go runtime signal dispatcher
func dispatchSignal(s os.Signal) {
// Find all channels waiting for this signal
channels := getListenersFor(s)
for _, c := range channels {
// Try to send the signal to channel 'c'
select {
case c <- s:
// Success! The channel had space.
default:
// Warning! The channel is full or not ready.
// Go runtime drops the signal and moves on!
}
}
}
The new method:
// 1 & 2. Create context and listen for signals in one line
ctx, stop := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
// Clean up resources when done
defer stop()
// 3. Wait for the context to be canceled
<-ctx.Done()
A complete example of a modern HTTP graceful shutdown.
package main
import (
"context"
"fmt"
"log"
"net/http"
"os/signal"
"syscall"
"time"
)
func main() {
// Create a context that listens for system signals
ctx, stop := signal.NotifyContext(context.Background(), syscall.SIGINT, syscall.SIGTERM)
// Ensure we release the signal resources when main ends
defer stop()
// Setup a simple HTTP server
srv := &http.Server{
Addr: ":8080",
Handler: http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// Sleep for 3 seconds to test slow requests
time.Sleep(3 * time.Second)
fmt.Fprintln(w, "Hello, modern Go!")
}),
}
// Start the server in a new goroutine
go func() {
log.Println("Server is running on port 8080...")
if err := srv.ListenAndServe(); err != nil && err != http.ErrServerClosed {
log.Fatalf("Server error: %v", err)
}
}()
// Block main goroutine here until we get a signal
<-ctx.Done()
// Stop listening for signals right now.
// This means a second Ctrl+C will kill the app instantly.
stop()
log.Println("Signal received. Starting graceful shutdown...")
// Create a new context with a 5-second timeout for the shutdown process
shutdownCtx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// Shut down the server safely
if err := srv.Shutdown(shutdownCtx); err != nil {
log.Fatalf("Server forced to stop: %v", err)
}
log.Println("Server stopped safely.")
}
3. Error Handing: Create Custom Error Types Wherever Suitable。
Because error is an interface, you can build custom error types with extra functionality as long as they implement Error() string.
4. 性能优化
golang性能的瓶颈: make从heap分配内存的开销,频繁gc的压力
高效拼接字符串?
尽量不要用加号,每次拼接都会创建新字符串,导致大量内存分配和拷贝 1. 使用 strings.Builder 或 bytes.Buffer,避免多次内存分配。2. 已经有一个字符串切片时,这是最简洁高效的方式:string.Join() 3. 如果最终要写入 io.Writer(如文件、HTTP 响应),直接用 strings.Builder 的 WriteTo,避免转成字符串. builder.Grow(1024)
make切片时预分配容量,避免运行时扩容。
对象池模式(Object Pool Pattern)
🎯 为什么需要对象池?有些对象的创建/销毁成本很高,例如:
- 数据库连接(建立 TCP + 认证)
- 线程(操作系统资源)
- 大型结构体或带缓冲区的对象(如 bytes.Buffer、网络包解析器)
- 图形渲染中的纹理、粒子
如果每次用完就丢弃,下次再新建,会导致:
- 频繁 GC(垃圾回收)
- 系统调用开销大
- 内存碎片
graph LR
A[客户端需要对象] --> B{池中有空闲对象?}
B -- 有 --> C[从池中取出一个]
B -- 无 --> D[创建新对象]
C --> E[使用对象]
D --> E
E --> F[用完后归还到池]
F --> G[重置对象状态]
G --> H[等待下次被借出]
Go 中的经典例子:sync.Pool, 复用 bytes.Buffer
var bufferPool = sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
}
func process(data []byte) string {
// 1. 借对象
buf := bufferPool.Get().(*bytes.Buffer)
buf.Reset() // 重要:清空旧数据!
// 2. 使用
buf.Write(data)
result := buf.String()
// 3. 归还
bufferPool.Put(buf)
return result
}
设计模式
The Functional Options Pattern
Bad:
// 常规写法: 每次增加参数,所有调用者都会报错!
func NewServer(host string, port int, timeout time.Duration, maxConn int) *Server { ... }
// 调用时非常恶心,你必须记住参数顺序,不想设置的值也要瞎传
server := NewServer("localhost", 8080, 0, 0)
// 结构体作为初始化参数
// 缺陷:处理默认值非常头疼。比如 timeout 传了 0,代表用户想禁用超时,还是用户忘了传(应该用默认值 30s)?Go 里的零值很难区分这两种语义
type Config struct { ... }
func NewServer(cfg Config) *Server { ... }
Good:
package server
import (
"fmt"
"time"
)
// 1. 定义核心结构体和 Option 类型
type Server struct {
Host string
Port int
Timeout time.Duration
MaxConns int
}
type Option func(*Server)
// 2. 提供具体的配置函数 (With... 开头)
func WithHost(host string) Option {
return func(s *Server) {
s.Host = host
}
}
func WithPort(port int) Option {
return func(s *Server) {
s.Port = port
}
}
func WithTimeout(timeout time.Duration) Option {
return func(s *Server) {
s.Timeout = timeout
}
}
func WithMaxConns(maxConns int) Option {
return func(s *Server) {
s.MaxConns = maxConns
}
}
// 3. 编写构造函数 (New...)
func NewServer(opts ...Option) *Server {
// a. 初始化默认值 (Default configuration)
s := &Server{
Host: "127.0.0.1",
Port: 8080,
Timeout: 30 * time.Second,
MaxConns: 100,
}
// b. 遍历并应用所有的 Option (覆盖默认值)
for _, opt := range opts {
opt(s) // 执行传入的函数,修改 s 的字段
}
return s
}
func (s *Server) Start() {
fmt.Printf("Server starting on %s:%d, Timeout: %v, MaxConns: %d\n",
s.Host, s.Port, s.Timeout, s.MaxConns)
}
原理是定义一个可修改结构体的函数,将该函数作为参数传入“构造”函数,因此可以在构造的过程修改该结构体的参数。高可读,可配置,Backward Compatibility。
Factory Pattern
面向接口编程,隐藏具体实现。在 Go 中实现彻底解耦的工厂模式,有三个关键步骤:
- 服务端定义接口(抽象)。
- 服务端实现具体逻辑,但将结构体私有化(首字母小写)。
- 服务端提供一个公开的工厂函数,返回该接口。
通过这种设计,客户端只能通过工厂函数获取实例,且只知道接口有哪些方法,完全不知道底层的具体结构体是什么。这就实现了完美的物理层和逻辑层解耦。
package main
// Define the behavior
type Storage interface {
Save(data []byte) error
}
// Disk storage implementation
type Disk struct{}
func (d *Disk) Save(data []byte) error {
return nil
}
// Memory storage implementation
type Memory struct{}
func (m *Memory) Save(data []byte) error {
return nil
}
// Factory function returns the interface
func NewStorage(useDisk bool) Storage {
if useDisk {
return &Disk{}
}
return &Memory{}
}
If a function can return different underlying types based on the input parameters, you must return an interface. This allows the caller to interact with the behavior without knowing which specific struct was created under the hood.
The decorator pattern
The decorator pattern is a structural design pattern that allows augmenting an object’s behaviour without altering its core structure. In Go, this pattern is especially powerful when separating concerns like caching, logging, or instrumentation from your core business logic.
type CachedSource struct {
Source DataSource
Cache map[string]string
}
func (c *CachedSource) Get(id string) (string, error) {
// 1. Check cache
if val, ok := c.Cache[id]; ok {
log.Printf("Cache Hit for %s", id)
return val, nil
}
// 2. Call underlying source if not in cache
val, err := c.Source.Get(id)
if err != nil {
return "", err
}
// 3. Update cache
c.Cache[id] = val
return val, nil
}
不会修改原先的数据结构,通过装饰器(结构体嵌入),新增了新的行为。上述的示例就是数据库读取增加了优先内存缓存读取的方法。
Enhancing Data Access with the Decorator Pattern in Go
适配器模式
自己定义接口和实现接口,为原先的数据结构新增了新的行为。
Problem Solving
Dual-Writes and the Outbox Pattern
When working on any distributed system, you might need to write data into different sources and guarantee that there is still consistency across all systems. The dual-write problem comes when you need to write data to multiple systems atomically. Because you’re dealing with a distributed system, you can’t use atomic transactions, so if one write fails, the other system can be left in an inconsistent state.
Example: Your daily reconciliation job flags a problem: dozens of orders exist in your database, but no corresponding events ever reached Kafka. The email service never sent confirmations. The inventory service never reserved stock. After some digging, you find the culprit - Kafka had a brief hiccup yesterday and returned errors for a few publish attempts. The database writes succeeded, but without the outbox pattern, those events were simply lost.

A common strategy to mitigate the dual-write problem is the transactional outbox pattern, which relies on database transactions to update two tables: the table your app wants to update and an outbox table. The idea is to use atomic database transactions to ensure the write is successful in the two tables of your database. Once the write is successful, you can use a separate process to consume it from the outbox table and update any other service.
- Handling the Dual-Write Problem in Distributed Systems: Five Strategies
- Dual-Writes and the Outbox Pattern
利用本地数据库原子事务,同时写业务表和outbox事件表;独立服务轮询 outbox 表,异步同步至 OpenFGA,成功则标记事件为已处理。
Distributed Tracing
技术工具: 喜鹊开发者
- End-to-End tests with Venom yaml格式的测试用例。
- OpenFGA is
数据库之 Redis
核心:Redis 将所有数据存储在 RAM(内存) 中。 特性:
- 支持5种数据类型: 字符串, 列表, 集合, 哈希, 位图
- 定时对内存数据做快照存入磁盘
Redis 是通过消耗昂贵的内存来换取极致的速度;而 LSM-Tree 则是通过聪明的算法设计,在廉价的磁盘上实现了接近内存的写入表现 。
缓存雪崩:
极短的时间内,由于大量的缓存同时失效(过期)或缓存服务(Redis)宕机,导致原本应该由缓存处理的请求全部涌向后端数据库。
诱因:
- 大规模 Key 集中过期:为大量数据设置了相同的 TTL(生存时间),导致它们在同一秒失效。
- Redis 实例宕机:缓存层彻底失效,所有流量直接穿透到 DB。
应对策略
A. 事前预防:
- 防止 Key 集中失效 , TTL = Default_TTL + Random_Offset
- 热点数据永不过期。对于极高频访问的数据(如配置、大促首页数据),不设置过期时间,或者由后台逻辑异步更新。
- 使用 Redis Sentinel(哨兵模式) 或 Redis Cluster(集群模式),避免单点故障导致整个缓存层崩溃。
- 数据预热: 在系统上线或流量高峰到来前,手动将热点数据加载到 Redis 中,并错开过期时间。
B. 事中保护:防止数据库被压垮
- 服务熔断与限流: 使用 Sentinel 或 Hystrix 等工具。当检测到数据库压力过载时,直接返回错误或默认降级数据,牺牲部分体验保住系统。
- 加锁排队(互斥锁): 当缓存失效时,只允许一个请求去查询数据库并回写缓存,其他请求等待。
Golang 实现示例: 利用 sync.Mutex 或 singleflight 包。 C++ 实现示例: 利用 std::mutex 或分布式锁。
C. 事后容灾:快速恢复 多级缓存架构: 使用 本地缓存(如 Go 的 FreeCache 或 C++ 的内存 Map) + Redis 的二级缓存模式。即使 Redis 挂了,本地缓存也能抵挡一阵。
数据库之HBase– 高可靠、高性能的列式分布式存储系统
优点:
- 强大的随机存储能力。 通常大数据系统(如 Hive)只适合做批处理(很慢),但 HBase 可以在几毫秒内从数亿行数据中查找到某一行。B 站、阿里、X (Twitter) 常用它来存储历史数据、用户画像或聊天记录。
- 稀疏性(Sparse)。在 MySQL 中,如果你定义了 100 列但只填了 1 列,剩下的 99 列也占空间。但在 HBase 中,空的列完全不占存储空间。这非常适合处理那种“属性非常多,但每个对象只有几个属性”的数据。
- 自动分片 当你的数据表变得极其巨大时,HBase 会自动把表横向切分成很多份(称为 Region),分布到不同的服务器上。
底层原理
HBase 的底层数据结构非常精妙,它并不是像传统数据库那样直接把数据写在磁盘的固定位置,而是采用了 LSM 树(Log-Structured Merge-tree) 架构。
应用示例
应用示例,开发微信朋友圈:
- MySQL:存储你的账号、密码、昵称(数据量小,要求高度一致)。
- Kafka:当你发了一条朋友圈,这个动作先发到 Kafka。
- HBase:存储千万级用户发过的无数条朋友圈内容。因为朋友圈数据是稀疏的(有人发图,有人发文字,有人带地点),且量级巨大。
Kafka – distributed event streaming platform
对消息队列的直觉: 消息中间件(Message Middleware)的本质是一个“队列”,它遵循最基本的 FIFO(先进先出) 原则。生产者负责写入(发布),消费者负责读取(订阅)。
- 为什么“循环队列”是一个好的类比?
- 解耦: 生产者不需要知道消费者的存在,只需要把数据丢进“桶”里。
- 缓冲: 当生产速度快于消费速度时,队列充当了蓄水池的角色,防止消费者被瞬间流量冲垮。
- 为什么它不仅仅是一个循环队列?
- A. 持久化 (Persistence)
- B. 发布/订阅 (Pub/Sub) 与 扇出 (Fan-out) 中间件是支持广播的,不想队列点对点。
- C. 路由与交换 (Routing & Exchange)。RabbitMQ,它在生产者和队列之间加了一层 Exchange。它可以根据“路由键(Routing Key)”决定把消息发给哪一个或哪几个队列,而不仅仅是简单地往一个循环队列里写。
关于kafka
- 不是消息队列,Kafka 实现了消息队列的核心功能。
- 更是分布式日志系统(Distributed Commit Log)
传统 MQ 在消息被消费后通常会立即删除。而 Kafka 会把消息持久化到磁盘上,并且可以设置保留时间(比如保留 7 天)。 回溯消费:因为消息是持久化存储的,你可以让消费者“倒带”,重新消费过去的数据。 顺序性:它像记账本一样,严格按照进入的顺序追加记录。
流处理平台:
- 发布与订阅:类似于消息队列。消息队列(Kafka)存在的意义就是解耦(Decoupling)。
- 存储:可以作为高可靠的分布式存储。
- 实时处理:配合 Kafka Streams 或 Flink,它可以直接对流动中的数据进行计算(比如统计过去 1 分钟内的推文热度)。
核心概念:
- 生产者向 Topic 写数据,消费者从 Topic 读数据。
- 可指定 key,相同 key 的消息会落到同一 partition(保证顺序)。
- Broker(代理节点),Kafka 集群中的一个服务器实例。
+-------------+ +-------------------+ +------------------+
| | | | | |
| Producer |---->| Kafka Topic |---->| Consumer Group |
| (写入消息) | | (分区0,1,2...) | | (消费消息) |
| | | | | |
+-------------+ +-------------------+ +------------------+
↑
Broker 集群
(多台服务器组成)
架构设计:Kafka + HBase
- Kafka (缓冲层):用户每秒产生 100 万次点击,直接写数据库会把数据库冲垮。所以先扔进 Kafka。
- Flink/Go 程序 (处理层):从 Kafka 读出数据,做简单的清洗或聚合。
- HBase (存储层):把处理后的数据永久存入 HBase,供后续的后台系统查询。
Kratos
介绍:Kratos 是 B 站(Bilibili)开源的一套轻量级 Go 微服务框架。它最大的特点是“面向接口编程”,深度参考了 Google 内部的微服务设计哲学,大量使用了工程界最严谨的实践。
核心:Kratos 使用Protobuf来定义接口(gRPC/HTTP)、生成代码以及进行高效的微服务间通信 。
- Protobuf 为中心:先定义 .proto 文件,再生成代码。接口协议、路由、甚至是错误码都在 Proto 里。
- 依赖注入 (Wire):它不鼓励你手动在 main 函数里 new 各种对象,而是使用 Google 开源的 Wire 工具自动生成初始化代码。
- 标准 Context 传递: Kratos 强制每个层级都传递 context.Context,用于链路追踪和超时控制。
protobuf – 相当于二进制版的json
syntax = "proto3"; // 使用 proto3 语法
package api.v1;
option go_package = "helloworld/api/v1;v1";
// 定义一个“消息”结构
message User {
int32 id = 1; // 这里的 1, 2, 3 是字段编号(核心,不可随便改)
string name = 2;
string email = 3;
}
// 定义一个“服务”(用于 Kratos 或 gRPC)
service UserService {
rpc GetUser (UserRequest) returns (User);
}
message UserRequest {
int32 id = 1;
}
使用 protoc 工具(或者 Kratos 封装好的 kratos proto client 命令)来创建go文件。
生成的代码用法非常示例:
package main
import (
"fmt"
"log"
"google.golang.org/protobuf/proto"
"your_project/api/v1" // 导入生成的 pb 包
)
func main() {
// 1. 创建并填充数据
u := &v1.User{
Id: 1001,
Name: "Gemini",
Email: "ai@example.com",
}
// 2. 序列化:将结构体转为二进制(用于发给 Kafka 或 gRPC 调用)
data, err := proto.Marshal(u)
if err != nil {
log.Fatal("Marshaling error: ", err)
}
// 此时 data 是非常紧凑的二进制字节流
fmt.Printf("二进制长度: %d 字节\n", len(data))
// 3. 反序列化:将二进制转回结构体
u2 := &v1.User{}
if err := proto.Unmarshal(data, u2); err != nil {
log.Fatal("Unmarshaling error: ", err)
}
fmt.Printf("解码后的用户名: %s\n", u2.GetName())
}
K8s
Kubernetes(K8s) = 自动化容器编排平台
| K8s 概念 | 生活比喻 | 技术解释 |
|---|---|---|
| Node(节点) | 一台物理/虚拟服务器 | 运行容器的机器(Worker Node) |
| Pod | 一个“最小工作单元” | 一个或多个紧密耦合的容器(共享网络/存储) ✅ Pod 是 K8s 调度的最小单位 |
| Deployment | “我要 3 个用户服务实例” | 声明 Pod 的期望数量、镜像版本、更新策略 |
| Service | “给用户服务起个名字:user-svc” | 为 Pod 提供稳定 IP + DNS 名字 + 负载均衡 |
| kubectl | 管家的对讲机 | 你和 K8s 集群通信的命令行工具 |
重点:你几乎永远不会直接操作 Pod,而是通过 Deployment 管理它。
K8s 如何实现“自动化”?
场景:一个 Pod 挂了
- K8s 的 kubelet(每台 Node 上的代理)发现 Pod 死了
- Controller Manager(控制平面组件)对比“当前状态” vs “期望状态”(Deployment 说要 2 个)
- 自动创建一个新 Pod 补上
- Service 自动把流量导向新 Pod
整个过程无需人工干预。
作为开发者,只和 API Server 交互(通过 kubectl 或 YAML)。
Kubernetes 的核心架构,Control Plane 和 Worker Node 各包含哪些关键组件?
Control Plane(控制平面):
- kube-apiserver:集群的唯一入口,所有操作都通过它。
- etcd:分布式键值存储,保存集群所有状态。
- kube-scheduler:负责将 Pod 调度到合适的 Node。
- kube-controller-manager:运行各种控制器(如 Deployment、Node 控制器)。
- cloud-controller-manager(云厂商相关)。
Worker Node(工作节点):
- kubelet:管理本机 Pod 和容器。
- kube-proxy:实现 Service 网络代理和负载均衡。
- 容器运行时(如 containerd、Docker)。
Restful API
其他
“五分钟法则”(Five Minute Rule)
Jim Gray 在 1987 年提出,旨在确定何时应该将数据保留在内存中以避免磁盘访问 。 五分钟法则指出,如果一个页面的访问频率足够高(例如每 60 秒或更短时间被引用一次),那么购买内存来缓存该页面比支付磁盘 I/O 带来的系统成本更低 。
JSF++ 标准与防御式编程
SF++ 编码标准(全称:Joint Strike Fighter C++ Coding Standards)是目前嵌入式 C++ 领域最著名、最严苛的编码规范之一。它是专门为 F-35 闪电 II 战斗机(Joint Strike Fighter) 项目设计的,目的是确保其高达数百万行的任务关键型(Mission-Critical)代码具有极高的安全性、可靠性和可测试性。
JSF++ 的核心理念是:如果一个特性可能导致不可预测的行为,那么直接禁用它。
在 F-35 这种最高安全等级的航空航天项目中,Green Hills Software (GHS, 链接) 的编译器是行业标准。DDC-I:这是另一个在航天领域非常著名的编译器供应商,专门提供满足实时性要求的 C++ 工具链。Stroustrup 在 2005 年论文中提到的,硬实时系统需要预测每一个时钟周期。
- 禁用动态内存分配 (No Heap)。动态分配会导致内存碎片化和执行时间不确定。在战斗机飞行中,系统绝不能因为“内存垃圾回收”或“申请不到空间”而卡顿。
- 异常处理的限制 (No Exceptions)
- 禁用运行时类型识别 (No RTTI)
- 确定性的递归 (No Unbounded Recursion)
- 禁止 goto
- 强制性注释:每一段代码必须有对应的需求编号,这种可追溯性是航天级开发的通用标准。
- 静态分析:JSF++ 要求代码必须能通过静态分析工具(如 LDRA 或 PRQA)的自动化检查。这意味着你的代码不仅要能跑,还要长得“标准”。
JSF++编码标准严格禁止在战斗机应用中使用的 C++代码库中使用异常和自由存储。由于自由存储的不确定性,标准库 std::string 和 std::vector、std::map 等容器应该被禁止,因为这些功能内部使用 new 和 delete,这使得它们同样不可预测。
SF++ 后来深刻影响了后来的 MISRA C++ 标准(汽车行业标准)和 AUTOSAR。
编程杂谈
前端知识汇总。
为什么操作 DOM 这么消耗性能?前端界有一个非常著名的比喻:“跨岛操作”。在浏览器中,JavaScript 引擎(比如 Chrome 的 V8)和渲染引擎(比如 Blink 或 WebKit)就像是两座独立的岛屿,中间由一座收费桥连接。 你每次用 JavaScript 去读取或修改 DOM,就等于交一次“过桥费”。偶尔过桥没问题,但如果你在一个循环里频繁过桥,哪怕每次只带一点点东西(比如插入一个 <li> 标签),高昂的“过桥费”和渲染引擎反复计算布局的开销,就会导致页面严重卡顿。
向优秀的开发者学习
Phil Haack 偶然看到Phil Haack 2007 年谈论测试驱动开发TDD的文章Career Chutes and Ladder,那时候他大约33岁在写ASP.NET。身为创业公司的合伙人,经常为了支付员工工资而放弃自己的薪水,当时他妻子怀孕压力很大。随后08年加入了微软担任高级项目经理。2011年他放弃了微软待遇优渥的高薪工作,再以低得多的薪水跳槽到当时名不见经传的小公司Github,用C#和WPF编写Git Windows客户端 和Atom。2018年(约43岁)从Github以工程总监的职位离职创业。从最初的开发人员到经理,从工程总监再到自己创业担任CTO,创业失败,24年休息了一年。2025 年,他加入了 PostHog 重回 IC (个人贡献者)。Phil 写代码估计25年左右,50多岁仍然在高强度贡献代码。
我对Phil的评价:
- 经历相当丰富,勤奋且性格的韧性极强。Phil认为职业生涯并非关乎完美的头衔,而是关乎经验、人脉和技能的积累,这些都会塑造你。
- 我认为他选错了技术栈,应该选择一门上限更高的语言,最好是可以面向系统编程的语言。
- 创业失败怎么说呢,这就是人生。
Kartik Singhal 从布朗大学到芝加哥,从事量子计算。 I also came to realize that to achieve my long term goals going back to the industry will not help. I was still interested in the sweet spot of systems and PL research that focuses on concurrency and figured that the right way forward will be to work in a research environment where I could focus on things that I really want to do. This realization and a lot of encouragement from people around me led to my decision to apply for a PhD. A common theme that I see in papers I really like is that they provide a fair bit of historical perspective on how big ideas in computing/systems emerged. 我也逐渐意识到,重返工业界并不能帮助我实现长期目标。我仍然对系统和编程语言研究的并发性领域充满热情,并认为正确的方向是在研究环境中工作,这样我就可以专注于自己真正想做的事情。这种认识以及周围人的鼓励促使我决定申请攻读博士学位。 我非常喜欢的论文中一个共同的主题是,它们都提供了相当多的历史视角, 阐述了计算机/系统领域重大思想的出现过程。
编程与AI
Bjarne Stroustrup:
First of all, I’m not a AI expert and I don’t plan to become one. So that’s an area I cannot pick up. I don’t have the backgroud, and I don’t have the time. I don’t have the people that could fire me up. I have some worries, you know, I’ve always got some worries. I’m trying to solve problems and to solve problems. You have to start worrying about something. But the thing that I see is that people are using LMMs to get answers, and there’s lot of stuff about letting them do the simple things. I worry that we lose the skills to determine what is good and what is correct, because we are not actually practicing doing things. We lose the ability to do it ourselves. And then we come to trust the AI. And the AI is at least now not trustworthy. And that is similar to when we started outsourcing and offshoring stuff, because it was cheaper and it worked beautifully for a couple of years until we lost the people who could actually do quality control on what was offshore. The skills were outsourced and such. And the companies that were doing it lost the ability to see what was good and bad. And then they got bloat from the outside. And I’m worrying what instead of being able to do fairly straghtforward things, we then have piles upon piles and tools and cross checks and double checks try and avoid the faults of the AI. But it’s so complicated, I will never become an expert on this.
- 我担心我们会失去判断好坏和辨别正确或错误的能力,因为我们实际上并没有实践过。我们失去了自己动手的能力。
- 我们信任AI, 但是目前的AI还不值得信任。与软件外包业务很相似,更便宜,直到公司失去了进行质量控制的员工。
- 原本我们可以简单直接的做事,后来我们开始用一堆工具试图避免AI的缺陷。
我担心人们因为太习惯于别人帮忙做,导致他们失去了发现问题的能力。
Why C++ programmers keep growing fast despite competition, safety, and AI
- First, I think that people who think AI isn’t a major game-changer are fooling themselves.
- Second, I think that people who think AI is going to put a large fraction of programmers out of work are fooling themselves.
- If your job is fundamentally “follow complex instructions and push buttons,” AI will come for it eventually.
AI 基础知识
- RNN(循环神经网络)的缺点: 1. 依赖前一次输入,无法并发。2. 梯度消失 (Vanishing Gradient)。玩“传声筒”游戏,传到第 100 个人时,最初的信息已经变得极其微弱甚至消失了。这导致它记不住长句子前面的内容。
- CNN(卷积神经网络)的问题:可以把 CNN 想象成一个 “拿着放大镜观察世界的侦探”。它观察局部很厉害,但全局观和灵活性上有些欠缺。 CNN 的池化(Pooling),它的目的是压缩信息,只保留最重要的特点。同一只猫,换个方向就不认识了。
如果你想从“驾驶员”进阶到“技师”,你只需要掌握以下三块的“直觉”,而不是去背公式:
- 线性代数(矩阵运算),直觉: 把一堆数据看成一个“表格”(矩阵),学习如何把两个表格叠在一起或乘在一起。这在处理图像(CNN)和文本时是基础。
- 微积分(导数/梯度), 直觉: 就是“下坡”。模型预测错了,得往哪个方向改才能错得少一点?导数就是指明那个“下坡最快方向”的路标。
- 概率统计,直觉: 机器学习本质上是在“猜”。统计学告诉我们,猜对的概率有多大,以及我们对这个结果有多大的信心。
推荐的学习路径:
- 先跑通: 找个教程,用 Python 跑通一个 MNIST 手写数字识别。
- 点对点爆破: 遇到不懂的术语(比如“损失函数”),再去查它背后的数学直觉。
- 图形化理解: 多看动图和可视化。数学是静态的,而机器学习是动态的优化过程
推特的开源算法
推特开源了他们的算法,https://github.com/xai-org/x-algorithm 。
- thunder筛选关注账户的帖子,放在内存。phoenix从所有的帖子中检索与用户向量最相似的1千条帖子。该两个数据源构成候选的帖子,采用异步获取。
- 对候选的帖添加补充信息。
- 预过滤器:移除重复的,屏蔽的帖子等。
- 打分和排序,作者多样性打分器。
- 按评分高低筛选前50条。
- 最终过滤:移除已删除或垃圾帖子等。
这个算法最核心的部分有两个:
- 一是筛选阶段phoenix的相似度计算,用户向量·帖子向量的点积运算;
- 二是对帖子的精细打分,从用户点赞、评论、转发、点击和举报等维度加权打分,计算每个帖子的评分。
技术细节:如果为每个用户保存1024向量,全球10亿用户则需要4TB。为节约存储空间,将1024分成四组256维向量,每组用一个独立的哈希函数。哲学意义上,可以理解为每个用户被压缩成抽象的4组特征,每个特征有10万种不同(哈希表的条数)。
该算法显然的弊端会导致信息收敛,因为数据源来自关注列表和ML打分出来相关度高的帖子。最终推荐给用户的内容,其中就只剩下用户想看的内容,信息茧房或者说收敛。应当加入一些热门或随机的东西,让信息发散。
zendesk服务
这个服务很有意思,致力于简化客户和公司之间的客户解决方案。这是一个在细分领域成功创业的想法,特别棒的idea。在未来当互联网的基础设置被巨头垄断时,初创公司想要在互联网分一杯羹,他们就要从细分领域着眼。认真考虑用户的需求,考虑公司的需求,尤其这种看起来毫不起眼的。
对软件更新过快的抱怨
我的一些软件总是频繁提示更新,这么多开发者和企业热衷于快速迭代更新。让我感到厌恶。最好的软件应该只发布一次,并且最好永远不再更新。我对那些新功能和特性完全没有感兴趣,我只是需要一个足够稳定的版本,没有bug,辅助完成我的工作。我相信80%的用户只用了软件20%的功能,然而,80%的功能特性不到20%的用户在使用。
为什么要试图囊括所有的需求呢?我能理解这背后的原因:开发者和产品经理拿了薪水,他们总是在不停寻找新的特性加入,以证明自己的工作价值以免被炒鱿鱼,老板也很乐意自己的软件在变得强大。然而,用户真的需要那些新特性吗?这是一个值得他们停下来去思考的问题。起码我希望自己的这些软件可以停止更新。或者提供两个不同更新频率的版本:低更新频率的「稳定版」和高频率更新的「开发版」,来满足两种风格不同的用户。
2022-01-02
关于我的兴趣
到现在我还不知道我的兴趣聚焦于哪个点,所以我尽可能了解更多,学习更多。不过我知道我喜欢编程语言中有意思的概念,有意思的想法。我想我的好奇心会帮助我找到最终的答案,让我的工作有一个核心的关注点。
我对于计算机中一些个人口味的不喜欢是显而易见的,比如:计算机图形学,密码学,我对这些基本上没有兴趣。我在从前工作了解过关于RSA密钥的算法,只是为了满足老板的商业需要进行学习的。比如我对LSM的数据结构有兴趣,所以我觉得自己关注的方向还是编程语言方向,关心数据结构和算法。我对Knuth的CWEB编程语言很感兴趣,它将是我这段时间忙完之后第一件事情。
关于编程语言工程实践的书
我不太喜欢看这类书,比如一些人推荐《代码大全》,重构这类的书。因为正如我前面所说的观念: 美是一种共识。
只要追求美,最终就会够殊途同归。如果年轻时代码写的不够美,只是因为对美的理解不够深刻,只要保持这种追求,最终就会自己独立的找到。如果你觉得能找到一种和一些方法就能够写出美的代码,我觉得这是误解和想当然。只要有了自己对美的理解,自然就能做出美的东西,而不需要任何专注所谓的”技巧“。有个词语叫”洗心革面“,只要”洗了心“,人的面貌自然就新了,而不需要”革面“。不能做表面工作侧重形式,而是专注于内在。
一个人应该学习几门编程语言?
Bjarne Stroustrup(Interview):
First of all, nobody should call themselves a professional if they only knew one language.” And five is a good number of languages to know reasonably well. And then you’ll know a bunch, just because you’re interested, because you’ve read about them, because you’ve written a couple of little programs. But five isn’t a bad number. Some of them books between three and seven. Let’s see, well my list is going to be sort of uninteresting because it’s going to be the list of languages that are best known and useful, I’m afraid. Let’s see, C++,of course; Java; maybe Python for mainline work. And if you know those, you can’t help knowing sort of a little bit about Ruby and JavaScript, you can’t help knowing C because that’s what fills out the domain and of course C#. But again, these languages create a cluster so that if you knew either five of the ones that I said, you would actually know the others. I haven’t cheated with the numbers. I rounded out a design space. It would be nice beyond that to know something quite weird outside it just to have an experience, pick one of the functional languages, for instance, that’s good to keep your head spinning a bit when it needs to. I don’t have any favorites in that field. There’s enough of them. And, I don’t know, if you’re interested in high-performance numerical computation, you have to look at one of the languages there, but for most people that’s just esoteric.
Peter Norvig:
Learn at least a half dozen programming languages. Include one language that emphasizes class abstractions (like Java or C++), one that emphasizes functional abstraction (like Lisp or ML or Haskell), one that supports syntactic abstraction (like Lisp), one that supports declarative specifications (like Prolog or C++ templates), and one that emphasizes parallelism (like Clojure or Go).
一门编程语言就只是一门编程语言。它和你是不是一个优秀的程序员没有关系,它只是语法。
评网页设计
对于网页设计,最好的设计就是没有其它任何无用的设计。
比如cppreference.com 这个网站,简洁的排版,突出主要的功能,广告也很少。类似的还有filezilla。这些网页的功能共同特点是一点也不花哨,该有的功能全都有。
现在的网站大都各种花里胡哨的,看起来炫酷,实际没有什么屁用。用户需要从网页上获取有用的信息,而不是被那些奇怪炫酷的东西吸引注意力。我不知道人们把注意力放在让网站变得更“炫酷”的意义在哪里,就好像青春期的小屁孩剪了个“爆炸”的发型。一切毫无意义的交互动作、过度的渲染,UI设计,无聊的横幅和图标,全是狗屎。
人们就像喜鹊一样,喜欢闪亮的东西。但时髦的东西并不一定是最好的。reddit有个评论写到(链接): “我们有一个市场营销天才,他把所有这些愚蠢的东西放在我们的网站上,我们的客户群扩大了一倍。我不明白,但这是商人喜欢的”。
2021-10-20
谈科学的门槛
科学的门槛越来越高了,以后只会是少数人的专利。在阿基米德时代,牛顿时代,你有一只笔、一些自制的“破铜烂铁”,有敏锐的洞察力和好奇心,就能做科学实验了。比如像孟德尔,种几亩豌豆也是正经的科学研究。
如今的科学,普通人要做实验需要各种仪器,没有足够的经费几乎是不可能的。普通人,与科学大院两者之间的壁垒只会越来越厚,随着学科发展,现代人掌握的知识要越来越多,而对未来人类的学习能力要求更高。我们还能回到过去那些不需要学历就能从事科学研究的时代吗?恐怕很难。
而计算机,我认为它仍然是一门新兴的学科,它的发展历史不到100年,依然有长足的潜力。我不知道什么是计算机未来真正正确的发展方向,我还在寻找。我希望自己走在正确的方向,我希望将这门科学在将来会更加完善,更加有趣。也许Donald Knuth会指引我,希望可以从他的著作中得到一些他的智慧。
2021-10-12
解释<薛定谔的猫>
薛定谔的猫,这个故事其实已经很形象了,但是仍有许多人不能理解它想表达的含义。它想表达的是思想是:“单个的微观事件是无法预测和准确测量的”。
假如你是一个微观粒子,那么你此时在家可能是在睡觉,或是在玩手机,或用电脑,或者在洗手间上厕所。但是不论你在做什么,我都无法知道。如果我想要知道,我就要闯入你的屋子,观察你在做什么。问题是一旦我闯入你家屋子,假如你在蹲马桶,可能就会立马提起裤子了;假如你在睡觉,就因此被我吵醒了。你会因为我的观测改变自己的行为,那么导致我观测的结果“并不准确”。
这就是薛定谔的猫,你永远不知道那只猫是死是活,也不知道它在做什么。这是量子理论最基本的概念。
2021-10-12
评论R语言
R语言的特点很明显: 数据类型足够丰富,但数据的操作很笨。如同去一家食物丰富的自助餐厅,但是老板却不提供刀叉,又不给盘子和火锅,到头来全靠手抓才能吃到嘴里。明显不如同样作为脚本语言和可用于科学计算的Python灵活。
数据灵活,但操作不灵活,在执行某些一连串操作时就会费劲——而不得不求助第三方包以快速解决问题。这是一门看起来简单的语言,但是隐藏的坑多,需要一些练习和技巧以后才能得心应手。相比之下,Python看起来简单,用起来也简单。
2021-10-11
穿孔纸带很酷!
Programmers Deal With the Legacy of Paper Tape Every Day
1960 年代初期,编写计算机程序的方式很有意思,使用穿孔纸带或者穿孔卡片。以纸带为例,上面3孔下面5孔,因为孔向一侧偏移就不会小不小心让纸带倒置。纸带中间有链轮孔,用于将它拉过阅读器。最下面的孔是奇偶校验位,因此从倒数第二位开始读起。有孔的地方读为1,没孔的地方读为0。
那么,图中的第一个字符是读作(1010100), 对应英文字符T。 第二字符读作(1101000),对应字符h。如此,就是一整个英文“This is PaperTaper \r\n”。对于\r\n字符的出现,它是为了标识代码行的结束。因为穿孔卡片一张卡片就是一行,而穿孔纸带是连续的,因此它要采用这样特殊方式标记一行结束。70年代的Unix开发者认为\r是多余的,因此如今经常只用\n作为结束。
在纸带上输入大量空格是一种浪费,因此tab符号就产生了,它表示告诉纸带的阅读机器直接跳到下一列编号(跳过8个字符)。如今物理键盘上的Tab已经不是当初的含义了,通常只是等同输入2或者4个空格。 换页符\f含义是跳到下一页的顶部,而垂直制表符\v会使页面向下跳到预设行列表中的下一页。今天,我们通常将这些字符视为简单的空格。BEL 字符让打字机内敲响个铃铛。NUL 字符则是因为纸带送入阅读器时,很难对齐它,前一排或前两排可能会损坏,因此前面的视为空白字符NUL。DEL字符比较实用,比如在纸带上输入了 500 行代码,就在代码即将完成时打错了一个字符。把纸带剪断不是一个好办法,那么直接在下个孔打满8个孔,表示逻辑上删除前一个字符。这也是为什么DEL字符总是ASCII码表的最后一个!它在纸带很明显。
2021-10-06
过早优化不总是万恶之源
Donald Knuth博士曾说过,”premature optimization is the root of all evil”(翻译: 过早优化是万恶之源). 这句话成了很多程序员写出糟糕代码的借口, 并且他们从来不试图优化自己的代码. 但是Knuth博士这句话的下半句很少有人知道: “ Yet we should not pass up our opportunities in that critical 3%”(而对于影响性能关键的 3%代码,我们则不能放弃优化的机会).
我在工作中就遇到过这样的事情, 在尝试修改少量的核心的代码, 其程序性能提升1~3倍. 如果放弃这样的优化机会, 将是很大的损失.
2021-09
待整理
Go 语言的创始人之一 Rob Pike 曾给出过一个非常精辟的总结:
并发 (Concurrency) 是关于程序的结构: 处理多个事情的能力(Dealing with lots of things at once)。
并行 (Parallelism) 是关于程序的执行: 同时执行多个事情的能力(Doing lots of things at once)。